Deep within your molecular biology are the paradoxical molecules called “Topoisomerase II”, which are potentially very dangerous in that they continuously and literally splice up your entire genome––and yet no life on Earth could ever exist or function without them. They temporarily induce immense damage to all your DNA…and then repair it perfectly. How this molecule functions on a near-atomic scale remains mostly a mystery but ALL life on Earth requires this molecule to exist and function, as do cancer cells. And it once also seemed that the key to finally curing cancer was to shut down this molecule so it cannot perform its function on DNA within cancerous cells.
In order for you to exist from microsecond to microsecond your entire genome–the sum total of your DNA–must be continuously maintained and regulated and repaired. This is done through an arsernal of enzymes, most crucially Topoisomerase II. The function of this enzyme/protein is to perform a crucial mathematical function: to remove knots and tangles and relieve overwinding/torsional stresses (positive supercoiling) within DNA. If DNA has knots or tangles, then tracking enzymes like RNA polymerase (responsible for protein transcription and renewing all your proteins) and DNA polymerase (which is initially responsible for DNA replication and thus cell division) could never function. They move along DNA like beads on a string and cannot proceed if they enounter knots or tangles.
However Topoisomerase II removes the DNA knots by performing a very dangerous “double-strand break” on your DNA.: Much like Alexander the Great’s solution to the Gordian Knot, they cut it open like a sword. The cut knot is ‘unknotted’ or removed and then the strand is resealed. However, it does more than that: it ensures DNA remains “underwound” or “negatively supercoiled” with a specific ‘Gaussian linking number’, (A formula first written down by Gauss in 1820.)). The DNA of all life on Earth shares this property.This molecule seems to know all the mathematical tricks from knot theory textbooks. However, at any instant, these molecules are splicing up your entire genome/DNA like scissors cutting string into billions of pieces…yet at the same time they reseal it all back together with all the knots removed…and so you continue to function and exist.
The class of cancer drugs called “Doxyrubicins” were designed to trap or ‘freeze’ Topoisomerase II so that the cancer DNA would remain knotted and tangled. Hence, it would not be able to replicate itself and the cancer cells would die. However, the cancer cells which survived the first rounds of treatment were able to unknot themselves with fewer Topoisomerase enzymes. Also, new genes can be turned on which enables the cells to expell the drug. Neverthleless, while not a cure, they have proven themselves to be effective drugs.”
……………………………………………………………………………………………………..(Follows closely: 738–748 Nucleic Acids Research, 2009, Vol. 37, No. 3) Topoisomerase II is an essential enzyme that is required for virtually every process that requires movement of DNA within the nucleus or the openingof the double helix. This enzyme helps to regulate DNA under- and overwinding and removes knots and tangles from the genetic material. In order to carry out its critical physiological functions, topoisomerase II generates transient double-stranded breaks in DNA. Consequently, while necessary for cell survival, the enzyme also has the capacity to fragment the genome. The DNA cleavage/ligation reaction of topoisomerase II is the target for some of the most successful anticancer drugs currently in clinical use. However, this same reaction also is believed to trigger chromosomal translocations that are associated with specific types of leukemia. This article will familiarize the reader with the DNA cleavage/ligation reaction of topoisomerase II and other aspects of its catalytic cycle. In addition, it will discuss the interaction of the enzyme with anticancer drugs and the mechanisms by which these agents increase levels of topoisomerase II-generated DNA strand breaks.
A number of enzymes that catalyze essential physiological processes also have the capacity to damage the genome during the course of their normal activities. For example, while the cell requires DNA polymerases to copy the genetic material, these enzymes insert an incorrect base approximately every 107 nt (1). Consequently, in the absence of mismatch repair pathways, human DNA
polymerases would generate several hundred mutations every round of cell division. Furthermore, while DNA glycosylases initiate base-excision repair pathways, these enzymes can convert innocuous lesions to abasic sites
with far greater mutagenic potential (2). Finally, while cytochrome P450 enzymes play critical roles in detoxification pathways, they sometimes convert inert xenobiotic chemicals to compounds with mutagenic properties (3). Of all the enzymes required to sustain cellular growth, topoisomerase II is one of the most dangerous (4–8). As discussed below, this enzyme unwinds, unknots and
untangles the genetic material by generating transient double-stranded breaks in DNA (8–12). Although the cell cannot survive without topoisomerase II, the strand breaks that the enzyme generates have the potential to trigger cell death pathways or chromosomal translocations.
This article focuses on the mechanism by which topoisomerase
II cleaves the genetic material, the ability to exploit this reaction for the chemotherapeutic treatment of human cancers and the role of this reaction in triggering specific types of leukemia.
DNA TOPOLOGY
The existence of topoisomerases is necessitated by the structure of the double helix. Each human cell contains 2m of DNA that are compacted into a nucleus that is 10 mm in diameter (14,15). Because the genetic material is anchored to the chromosome scaffold and the two strands of the double helix are plectonemically coiled, accessing the genome is a complex topological challenge (11,12,16–18). Topological properties of DNA are those that can only be changed when the double helix is broken (12). Two aspects of DNA topology significantly affect nuclear processes. The first deals with topological relationships between the two strands of the double helix.
In all living systems, from bacteria to humans, DNA is globally underwound
(i.e. negatively supercoiled) by 6% (12,19–21). This is important because duplex DNA is merely the storage form for the genetic information. In order to
replicate or express, DNA must be separated. Since global underwinding of
the genome imparts increased single-stranded character to the double helix, negative supercoiling greatly facilitates strand separation (12,16–18). While negative supercoiling promotes many nucleic acid processes, DNA overwinding (i.e. positive supercoiling) inhibits them. The linear movement of tracking enzymes, such as helicases and polymerases, compresses the turns of the double helix into a shorter region (Figure 1) (12,19–21). Consequently, the double helix becomes increasingly overwound ahead of tracking systems. The positive supercoiling that results makes it more difficult to open the two strands of the double helix and ultimately blocks essential nucleic acid processes (10,12,16–18). The second aspect of DNA topology deals with relationships between separate DNA segments. Intramolecular knots (formed within the same DNA molecule) are
generated during recombination, and intermolecular tangles (formed between daughter DNA molecules) are produced during replication (Figure 1) (8,10,12,17).
DNA knots block essential nucleic acid processes because they make it impossible to separate the two strands of the double helix. Moreover, tangled DNA molecules cannot be segregated during mitosis or meiosis (8,10,12,17). Consequently, DNA knots and tangles can be lethal to cells if they are not resolved.
DNA TOPOISOMERASES
The topological state of the genetic material is regulated by enzymes known as topoisomerases (8,10,11,22,23). Topoisomerases are required for the survival of all organisms and alter DNA topology by generating transient breaks in the double helix (8,10,11,22,23). There are two major classes of topoisomerases, type I and type II, that are distinguished by the number of DNA strands that they cleave and the mechanism by which they alter the topological properties of the genetic material (8,10,11,22,23). Eukaryotic type I topoisomerases are monomeric
enzymes that require no high-energy cofactor (11,22,24). Type I enzymes are organized into two subclasses: type IA and type IB. These enzymes alter topology by creating transient single-stranded breaks in the DNA, followed by passage of the opposite intact strand through the break (type IA) or by controlled rotation of the helix around the break (type IB) (11,22,24). Type IA topoisomerases need divalent metal ions for DNA scission and attach covalently to the 50-terminal phosphate of the DNA (11,22,24). In contrast, type IB enzymes do not require divalent metal ions and covalently link to the 30-terminal phosphate (11,22,24).
As a result of their reaction mechanism, type I topoisomerases can modulate
DNA under- and overwinding, but cannot remove knots or tangles from duplex DNA. A number of excellent review articles on type I topoisomerases have
appeared recently (22,24,25). Consequently, these enzymes will not be discussed further in this article. Eukaryotic type II topoisomerases function as homodimers and require divalent metal ions and ATP for complete catalytic activity (5,8,26–28). These enzymes interconvert different topological forms of DNA by a ‘double-stranded DNA passage reaction’ that can be separated into a number of discrete steps (5,8,26–28). Briefly, type II topoisomerases (i) bind two separate segments of DNA, (ii) create a double-stranded break in one of the segments, (iii) translocate the second DNA segment through the cleaved nucleic acid ‘gate’, (iv) rejoin (i.e. ligate) the cleaved DNA, (v) release the translocated segment through a gate in the protein and (vi) close the protein gate and regain the ability to start a new round of catalysis (5,26–34). Because of their double-stranded DNA passage mechanism, type II topoisomerases can modulate DNA supercoiling and also can remove DNAknots and tangles.
TOPOISOMERASE II
Lower eukaryotes and invertebrates encode only a single type II topoisomerase, topoisomerase II (35–38). In contrast, vertebrate species encode two closely related Nuclear processes induce changes in DNA topology. DNA replication is used as an example. Although chromosomal DNA is globally underwound in all cells, the movement of DNA tracking systems generates positive supercoils. As shown in (A) chromosomal DNA ends are tethered to membranes or the chromosome scaffold (represented by the red spheres) and are unable to rotate. Therefore, the linear movement of tracking systems (such as the replication machinery represented by the yellow bars) through the immobilized double helix
compresses the turns into a shorter segment of the genetic material and
induces acute overwinding (i.e. positive supercoiling) ahead of the fork
(B). In addition, the compensatory underwinding (i.e. negative supercoiling)
behind the replication machinery allows some of the torsional stress that accumulates in the prereplicated DNA to be translated to the newly replicated daughter molecules in the form of precatenanes (C). If these precatenanes are not resolved, they ultimately lead to the formation of intertwined (i.e. tangled) duplex daughter chromosomes. Adapted from ref. 10. Nucleic Acids Research, 2009, Vol. 37, No. 3 739 isoforms of the enzyme, topoisomerase IIa and topoisomerase IIb. These isoforms differ in their protomer molecular masses (170 versus 180 kDa, respectively) and are encoded by separate genes (8,10,22,28,39–46).
Topoisomerase IIa and topoisomerase IIb display a high degree (70%) of amino acid sequence identity and similar enzymological characteristics. One notable difference between the two isoforms is that topoisomerase IIa relaxes (i.e. removes) positive superhelical twists 10 times faster than it does negative in vitro, while the b isoform is unable to distinguish the geometry of DNA supercoils during DNA relaxation (47). Topoisomerase IIa and topoisomerase IIb have distinct patterns of expression and separate cellular functions. Topoisomerase IIa is essential for the survival of proliferating cells, and protein levels rise dramatically during periods of cell growth (48–51). The enzyme is further
regulated over the cell cycle, with protein concentrations peaking in G2/M (50,52,53). Topoisomerase IIa is associated with replication forks and remains tightly bound to chromosomes during mitosis (9,51,54–56). Thus, it is believed to be the isoform that functions in growth-related processes, such as DNA replication and chromosome segregation (10,51). Topoisomerase IIb is dispensable at the cellular level but appears to be required for proper neural development (57–59).
Expression of topoisomerase IIb is independent of proliferative status and cell cycle, and the enzyme dissociates from chromosomes during mitosis (54,60,61). Topoisomerase IIb cannot compensate for the loss of topoisomerase IIa in mammalian cells, suggesting that these two isoforms do not play redundant roles in replicative processes (51,60,62,63). Although the physiological functions of topoisomerase IIb have yet to be defined, recent evidence indicates involvement in the transcription of hormonally or developmentally regulated genes (63,64). Much of what we understand regarding the mechanism of action of type II enzymes comes from experiments with topoisomerase II from species that express only a single form of the protein. Consequently, eukaryotic type II
topoisomerases will be referred to collectively as topoisomerase
II, unless the properties being discussed are specific to either the a or b isoform.
TOPOISOMERASE II-MEDIATED DNA CLEAVAGE
AND LIGATION
The ability of topoisomerase II to cleave and ligate DNA is central to all of its catalytic functions (5,8,11,27). All topoisomerases utilize active site tyrosyl residues to mediate DNA cleavage and ligation. Since type II enzymes cut both strands of the double helix, each protomer subunit contains one of these residues (Tyr805 and Tyr821 in human topoisomerase IIa and topoisomerase IIb,
respectively). Topoisomerase II initiates DNA cleavage by the nucleophilic
attack of the active site tyrosine on the phosphate of the nucleic acid backbone (Figure 2) (11,23,26,27). The resulting transesterification reaction results in the
formation of a covalent phosphotyrosyl bond that links the protein to the newly generated 50-terminus of the DNA chain.
It also generates a 30-hydroxyl moiety on the opposite terminus of the cleaved strand. The scissile bonds on the two strands of the double helix are staggered and are located across the major groove from one another. Thus, topoisomerase II generates cleaved DNA molecules with four-base 50-single-stranded cohesive ends, each of which is covalently linked to a separate protomer subunit of the enzyme (65–67). The covalent enzyme–DNA linkage plays two important roles in the topoisomerase II reaction mechanism. First, it conserves the bond energy of the sugar-phosphate DNA backbone. Second, because it does not allow the cleaved DNA chain to dissociate from the enzyme, the protein– DNA linkage maintains the integrity of the genetic material during the cleavage event (11,23,26,27). The covalent topoisomerase II-cleaved DNA reaction intermediate is referred to as the ‘cleavage complex’ and is critical for the pharmacological activities of the enzyme, which are discussed later in this article.
Although topoisomerase II acts globally, it cleaves DNA at preferred sites (68). The consensus sequence for cleavage is weak, and many sites of action do not
conform to it (68). Ultimately, the mechanism by which topoisomerase II selects DNA sites is not apparent, and it is nearly impossible to predict de novo whether a given DNA sequence will support scission. Most likely, the specificity of topoisomerase II-mediated cleavage is determined by the local structure, flexibility, or malleability of the DNA that accompanies the sequence, as opposed
to a direct recognition of the bases that comprise that sequence (69). Beyond the nucleophilic attack of the active site tyrosine on the DNA backbone, the details of topoisomerase II mediated DNA cleavage are not well defined.


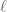
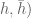





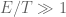


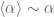
![Z_{n}=\sum_{\alpha=0}^{n}\exp[-\alpha{E}/T]\equiv\frac{1-\exp[-\beta(n+1)E}{1-exp[-\beta E]}](https://s0.wp.com/latex.php?latex=%C2%A0Z_%7Bn%7D%3D%5Csum_%7B%5Calpha%3D0%7D%5E%7Bn%7D%5Cexp%5B-%5Calpha%7BE%7D%2FT%5D%5Cequiv%5Cfrac%7B1-%5Cexp%5B-%5Cbeta%28n%2B1%29E%7D%7B1-exp%5B-%5Cbeta+E%5D%7D+&bg=ffffff&fg=545454&s=0&c=20201002)

![\langle\alpha\rangle=-\frac{1}{E}\frac{\partial \ln[Z_{n}]}{\partial\beta}](https://s0.wp.com/latex.php?latex=%C2%A0%5Clangle%5Calpha%5Crangle%3D-%5Cfrac%7B1%7D%7BE%7D%5Cfrac%7B%5Cpartial+%5Cln%5BZ_%7Bn%7D%5D%7D%7B%5Cpartial%5Cbeta%7D&bg=ffffff&fg=545454&s=0&c=20201002)
![\langle\alpha\rangle = \frac{\sum_{\alpha=0}^{N}\alpha n\exp[-nE/T]}{\sum_{\alpha=0}^{n}\alpha \exp[-nE/T]}=\frac{\exp[-E/T]}{1 - \exp[-E/T]}-\frac{(n+1)\exp[-(n+1)E/T}{1-\exp[-(n+1)E/T]}](https://s0.wp.com/latex.php?latex=%C2%A0+%C2%A0%5Clangle%5Calpha%5Crangle+%3D+%5Cfrac%7B%5Csum_%7B%5Calpha%3D0%7D%5E%7BN%7D%5Calpha+n%5Cexp%5B-nE%2FT%5D%7D%7B%5Csum_%7B%5Calpha%3D0%7D%5E%7Bn%7D%5Calpha+%5Cexp%5B-nE%2FT%5D%7D%3D%5Cfrac%7B%5Cexp%5B-E%2FT%5D%7D%7B1+-+%5Cexp%5B-E%2FT%5D%7D-%5Cfrac%7B%28n%2B1%29%5Cexp%5B-%28n%2B1%29E%2FT%7D%7B1-%5Cexp%5B-%28n%2B1%29E%2FT%5D%7D+&bg=ffffff&fg=545454&s=0&c=20201002)

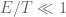




![C[Lk,T]](https://s0.wp.com/latex.php?latex=C%5BLk%2CT%5D&bg=ffffff&fg=545454&s=0&c=20201002)

![C[\mathcal{LK},T]=\frac{1}{Z}\exp[[-\Delta G/RT]\sim \frac{1}{Z}\exp[-K(\mathcal{Lk}-\mathcal{L}_{r})^{2}/R](https://s0.wp.com/latex.php?latex=%C2%A0C%5B%5Cmathcal%7BLK%7D%2CT%5D%3D%5Cfrac%7B1%7D%7BZ%7D%5Cexp%5B%5B-%5CDelta+G%2FRT%5D%5Csim+%5Cfrac%7B1%7D%7BZ%7D%5Cexp%5B-K%28%5Cmathcal%7BLk%7D-%5Cmathcal%7BL%7D_%7Br%7D%29%5E%7B2%7D%2FR+&bg=ffffff&fg=545454&s=0&c=20201002)


![C[\mathcal{LK},T]\rightarrow 0](https://s0.wp.com/latex.php?latex=C%5B%5Cmathcal%7BLK%7D%2CT%5D%5Crightarrow+0&bg=ffffff&fg=545454&s=0&c=20201002)


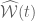



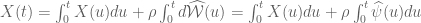





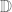
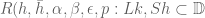
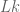

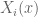

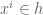

![W[h]=exp\bigg(i\int_{h}X_{i}(x)dx^{i}\bigg)=\exp(\tfrac{1}{2}i(\alpha^{2}+p^{2})^{1/2}Lk(h,\bar{h}))](https://s0.wp.com/latex.php?latex=%C2%A0+W%5Bh%5D%3Dexp%5Cbigg%28i%5Cint_%7Bh%7DX_%7Bi%7D%28x%29dx%5E%7Bi%7D%5Cbigg%29%3D%5Cexp%28%5Ctfrac%7B1%7D%7B2%7Di%28%5Calpha%5E%7B2%7D%2Bp%5E%7B2%7D%29%5E%7B1%2F2%7DLk%28h%2C%5Cbar%7Bh%7D%29%29+&bg=ffffff&fg=545454&s=0&c=20201002)
![W[\bar{h}]=exp\bigg(i\int_{\bar{h}}X_{i}(x)dx^{i}\bigg)=exp(\tfrac{1}{2}i(\alpha^{2}+p^{2})^{1/2} Lk(h,\bar{h}))](https://s0.wp.com/latex.php?latex=%C2%A0W%5B%5Cbar%7Bh%7D%5D%3Dexp%5Cbigg%28i%5Cint_%7B%5Cbar%7Bh%7D%7DX_%7Bi%7D%28x%29dx%5E%7Bi%7D%5Cbigg%29%3Dexp%28%5Ctfrac%7B1%7D%7B2%7Di%28%5Calpha%5E%7B2%7D%2Bp%5E%7B2%7D%29%5E%7B1%2F2%7D+Lk%28h%2C%5Cbar%7Bh%7D%29%29+&bg=ffffff&fg=545454&s=0&c=20201002)

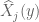
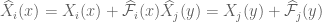


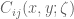

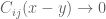
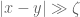
![W[h]=exp\bigg(i\int_{h}\widehat{X}_{i}(x)dx^{i}\bigg)=exp\bigg(i\int_{h}(\widehat{X}_{i}(x) +\widehat{\mathcal{F}}_{i}(x))dx^{i}\bigg)=exp(\tfrac{1}{2}i(\alpha^{2}+p^{2})^{1/2} Lk(h,\bar{h}))exp\bigg(i\int_{h}\widehat{\mathcal{F}}_{i}(x)dx^{i}\bigg)](https://s0.wp.com/latex.php?latex=%C2%A0W%5Bh%5D%3Dexp%5Cbigg%28i%5Cint_%7Bh%7D%5Cwidehat%7BX%7D_%7Bi%7D%28x%29dx%5E%7Bi%7D%5Cbigg%29%3Dexp%5Cbigg%28i%5Cint_%7Bh%7D%28%5Cwidehat%7BX%7D_%7Bi%7D%28x%29+%2B%5Cwidehat%7B%5Cmathcal%7BF%7D%7D_%7Bi%7D%28x%29%29dx%5E%7Bi%7D%5Cbigg%29%3Dexp%28%5Ctfrac%7B1%7D%7B2%7Di%28%5Calpha%5E%7B2%7D%2Bp%5E%7B2%7D%29%5E%7B1%2F2%7D+Lk%28h%2C%5Cbar%7Bh%7D%29%29exp%5Cbigg%28i%5Cint_%7Bh%7D%5Cwidehat%7B%5Cmathcal%7BF%7D%7D_%7Bi%7D%28x%29dx%5E%7Bi%7D%5Cbigg%29+&bg=ffffff&fg=545454&s=0&c=20201002)
![W[\bar{h}])=exp\bigg(i\int_{h}\widehat{X}_{i}(x)dx^{i}\bigg)=exp\bigg(i\int_{h}(\widehat{X}_{i}(x) +\widehat{\mathcal{F}}_{i}(x))dx^{i}\bigg)=exp(\tfrac{1}{2}i(\alpha^{2}+p^{2})^{1/2} Lk(h,\bar{h}))exp\bigg(i\int_{\bar{H}}\widehat{\mathcal{F}}_{i}(x)dx^{i}\bigg)](https://s0.wp.com/latex.php?latex=W%5B%5Cbar%7Bh%7D%5D%29%3Dexp%5Cbigg%28i%5Cint_%7Bh%7D%5Cwidehat%7BX%7D_%7Bi%7D%28x%29dx%5E%7Bi%7D%5Cbigg%29%3Dexp%5Cbigg%28i%5Cint_%7Bh%7D%28%5Cwidehat%7BX%7D_%7Bi%7D%28x%29+%2B%5Cwidehat%7B%5Cmathcal%7BF%7D%7D_%7Bi%7D%28x%29%29dx%5E%7Bi%7D%5Cbigg%29%3Dexp%28%5Ctfrac%7B1%7D%7B2%7Di%28%5Calpha%5E%7B2%7D%2Bp%5E%7B2%7D%29%5E%7B1%2F2%7D+Lk%28h%2C%5Cbar%7Bh%7D%29%29exp%5Cbigg%28i%5Cint_%7B%5Cbar%7BH%7D%7D%5Cwidehat%7B%5Cmathcal%7BF%7D%7D_%7Bi%7D%28x%29dx%5E%7Bi%7D%5Cbigg%29+&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{W}[h]=\mathbf{E}(W[h])=\mathbf{E}\bigg(exp\bigg(i\int_{h}\widehat{X}_{i}(x)dx^{i}\bigg)\bigg)=exp\bigg(i\int_{h}(\widehat{X}_{i}(x) +\widehat{\mathcal{F}}_{i}(x))dx^{i}\bigg) = exp(\tfrac{1}{2}i(\alpha^{2}+p^{2})^{1/2} Lk(h,\bar{h}))\mathbf{E}\bigg(exp\bigg(i\int_{h}\widehat{\mathcal{F}}_{i}(x)dx^{i}\bigg)\bigg)](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BW%7D%5Bh%5D%3D%5Cmathbf%7BE%7D%28W%5Bh%5D%29%3D%5Cmathbf%7BE%7D%5Cbigg%28exp%5Cbigg%28i%5Cint_%7Bh%7D%5Cwidehat%7BX%7D_%7Bi%7D%28x%29dx%5E%7Bi%7D%5Cbigg%29%5Cbigg%29%3Dexp%5Cbigg%28i%5Cint_%7Bh%7D%28%5Cwidehat%7BX%7D_%7Bi%7D%28x%29+%2B%5Cwidehat%7B%5Cmathcal%7BF%7D%7D_%7Bi%7D%28x%29%29dx%5E%7Bi%7D%5Cbigg%29+%3D+%C2%A0exp%28%5Ctfrac%7B1%7D%7B2%7Di%28%5Calpha%5E%7B2%7D%2Bp%5E%7B2%7D%29%5E%7B1%2F2%7D+Lk%28h%2C%5Cbar%7Bh%7D%29%29%5Cmathbf%7BE%7D%5Cbigg%28exp%5Cbigg%28i%5Cint_%7Bh%7D%5Cwidehat%7B%5Cmathcal%7BF%7D%7D_%7Bi%7D%28x%29dx%5E%7Bi%7D%5Cbigg%29%5Cbigg%29+&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{W}[\bar{h}]=\mathbf{E}(W[H])=\mathbf{E}\bigg(exp\bigg(i\int_{h}\widehat{X}_{i}(x)dx^{i}\bigg)\bigg)= exp\bigg(i\int_{h}(\widehat{X}_{i}(x) +\widehat{\mathcal{F}}_{i}(x))dx^{i}\bigg)=exp(\tfrac{1}{2}i(\alpha^{2}+p^{2})^{1/2} Lk(h,\bar{h}))\mathbf{E}\bigg(exp\bigg(i\int_{\bar{h}}\widehat{\mathcal{F}}_{i}(x)dx^{i}\bigg)\bigg)](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BW%7D%5B%5Cbar%7Bh%7D%5D%3D%5Cmathbf%7BE%7D%28W%5BH%5D%29%3D%5Cmathbf%7BE%7D%5Cbigg%28exp%5Cbigg%28i%5Cint_%7Bh%7D%5Cwidehat%7BX%7D_%7Bi%7D%28x%29dx%5E%7Bi%7D%5Cbigg%29%5Cbigg%29%3D%C2%A0exp%5Cbigg%28i%5Cint_%7Bh%7D%28%5Cwidehat%7BX%7D_%7Bi%7D%28x%29+%2B%5Cwidehat%7B%5Cmathcal%7BF%7D%7D_%7Bi%7D%28x%29%29dx%5E%7Bi%7D%5Cbigg%29%3Dexp%28%5Ctfrac%7B1%7D%7B2%7Di%28%5Calpha%5E%7B2%7D%2Bp%5E%7B2%7D%29%5E%7B1%2F2%7D+Lk%28h%2C%5Cbar%7Bh%7D%29%29%5Cmathbf%7BE%7D%5Cbigg%28exp%5Cbigg%28i%5Cint_%7B%5Cbar%7Bh%7D%7D%5Cwidehat%7B%5Cmathcal%7BF%7D%7D_%7Bi%7D%28x%29dx%5E%7Bi%7D%5Cbigg%29%5Cbigg%29+&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{W}[h]=\mathbf{E}(\widehat{W}[h])=exp(\tfrac{1}{2}(\alpha^{2}+p^{2})^{1/2} Lk(h,\bar{h})\mathbf{\mathcal{W}}(h)](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BW%7D%5Bh%5D%3D%5Cmathbf%7BE%7D%28%5Cwidehat%7BW%7D%5Bh%5D%29%3Dexp%28%5Ctfrac%7B1%7D%7B2%7D%28%5Calpha%5E%7B2%7D%2Bp%5E%7B2%7D%29%5E%7B1%2F2%7D%C2%A0Lk%28h%2C%5Cbar%7Bh%7D%29%5Cmathbf%7B%5Cmathcal%7BW%7D%7D%28h%29+&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{W}[\bar{h}]=\mathbf{E}(\widehat{W}[h])=exp(\tfrac{1}{2}(\alpha^{2}+p^{2})^{1/2} Lk(h,\bar{h})\mathbf{\mathcal{W}}(\bar{h}](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BW%7D%5B%5Cbar%7Bh%7D%5D%3D%5Cmathbf%7BE%7D%28%5Cwidehat%7BW%7D%5Bh%5D%29%3Dexp%28%5Ctfrac%7B1%7D%7B2%7D%28%5Calpha%5E%7B2%7D%2Bp%5E%7B2%7D%29%5E%7B1%2F2%7D%C2%A0Lk%28h%2C%5Cbar%7Bh%7D%29%5Cmathbf%7B%5Cmathcal%7BW%7D%7D%28%5Cbar%7Bh%7D&bg=ffffff&fg=545454&s=0&c=20201002)
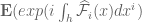
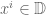



![\mathbf{W}[h]=\mathbf{E}(\widehat{W}[h])=exp(\tfrac{1}{2}(\alpha^{2}+p^{2})^{1/2} Lk(h,\bar{h})exp\bigg(-\int_{h}\int_{h}C_{ij}(x,y;\zeta)dx^{i}dy^{j}\bigg)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BW%7D%5Bh%5D%3D%5Cmathbf%7BE%7D%28%5Cwidehat%7BW%7D%5Bh%5D%29%3Dexp%28%5Ctfrac%7B1%7D%7B2%7D%28%5Calpha%5E%7B2%7D%2Bp%5E%7B2%7D%29%5E%7B1%2F2%7D%C2%A0Lk%28h%2C%5Cbar%7Bh%7D%29exp%5Cbigg%28-%5Cint_%7Bh%7D%5Cint_%7Bh%7DC_%7Bij%7D%28x%2Cy%3B%5Czeta%29dx%5E%7Bi%7Ddy%5E%7Bj%7D%5Cbigg%29&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{W}[\bar{h}]=\mathbf{E}(\widehat{W}[h])=exp(\tfrac{1}{2}(\alpha^{2}+p^{2})^{1/2} Lk(h,\bar{h})\exp\bigg(-\int_{h}\int_{\bar{h}}C_{ij}(x,y;\zeta)dx^{i}dy^{j}\bigg)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BW%7D%5B%5Cbar%7Bh%7D%5D%3D%5Cmathbf%7BE%7D%28%5Cwidehat%7BW%7D%5Bh%5D%29%3Dexp%28%5Ctfrac%7B1%7D%7B2%7D%28%5Calpha%5E%7B2%7D%2Bp%5E%7B2%7D%29%5E%7B1%2F2%7D%C2%A0Lk%28h%2C%5Cbar%7Bh%7D%29%5Cexp%5Cbigg%28-%5Cint_%7Bh%7D%5Cint_%7B%5Cbar%7Bh%7D%7DC_%7Bij%7D%28x%2Cy%3B%5Czeta%29dx%5E%7Bi%7Ddy%5E%7Bj%7D%5Cbigg%29+&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{W}[h]=\mathbf{E}(\widehat{W}[h])=exp(\tfrac{1}{2}(\alpha^{2}+p^{2})^{1/2}Lk(h,\bar{h})\exp (-Q_{ij})](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BW%7D%5Bh%5D%3D%5Cmathbf%7BE%7D%28%5Cwidehat%7BW%7D%5Bh%5D%29%3Dexp%28%5Ctfrac%7B1%7D%7B2%7D%28%5Calpha%5E%7B2%7D%2Bp%5E%7B2%7D%29%5E%7B1%2F2%7DLk%28h%2C%5Cbar%7Bh%7D%29%5Cexp+%28-Q_%7Bij%7D%29+&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{W}[\bar{h}]=\mathbf{E}(\widehat{W}[h])=exp(\tfrac{1}{2}(\alpha^{2}+p^{2})^{1/2} Lk(h,\bar{h})\exp(-Q_{ij})](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BW%7D%5B%5Cbar%7Bh%7D%5D%3D%5Cmathbf%7BE%7D%28%5Cwidehat%7BW%7D%5Bh%5D%29%3Dexp%28%5Ctfrac%7B1%7D%7B2%7D%28%5Calpha%5E%7B2%7D%2Bp%5E%7B2%7D%29%5E%7B1%2F2%7D%C2%A0Lk%28h%2C%5Cbar%7Bh%7D%29%5Cexp%28-Q_%7Bij%7D%29&bg=ffffff&fg=545454&s=0&c=20201002)



 has only zero eigenstates and the Hilbert space is finite. For a 3-manifold
has only zero eigenstates and the Hilbert space is finite. For a 3-manifold 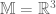 the VEV of the Wilson loop is
the VEV of the Wilson loop is![\langle W[K]\rangle = \int DA\exp(iS_{cs})W[K]](https://s0.wp.com/latex.php?latex=%5Clangle+W%5BK%5D%5Crangle+%3D+%5Cint+DA%5Cexp%28iS_%7Bcs%7D%29W%5BK%5D&bg=ffffff&fg=545454&s=0&c=20201002)
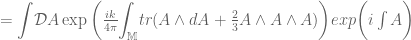
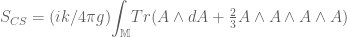
 and g=1, and
and g=1, and  is an
is an  connection or gauge field. The partition function
connection or gauge field. The partition function 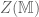 is itself an invariant (the Witten invariant) of the 3-manifold and can be calculated analytically. Witten (refs) demonstrated that this connects with the Jones polynomial of knot theory and the simple non-Abelian CS theory reproduces the Gaussian linking number
is itself an invariant (the Witten invariant) of the 3-manifold and can be calculated analytically. Witten (refs) demonstrated that this connects with the Jones polynomial of knot theory and the simple non-Abelian CS theory reproduces the Gaussian linking number![\langle W[K] \rangle = \int \mathcal{D}A exp \bigg (\frac{ik}{4\pi}{\displaystyle \int_{\mathbb{M}} }tr({A}\wedge d{A})\bigg) exp\bigg(i {\displaystyle \int} A\bigg)=exp(\mathbf{\mathcal{L}k}[K, K'])](https://s0.wp.com/latex.php?latex=%C2%A0%C2%A0%5Clangle+W%5BK%5D+%5Crangle+%C2%A0%3D+%C2%A0%5Cint+%5Cmathcal%7BD%7DA+exp+%5Cbigg+%28%5Cfrac%7Bik%7D%7B4%5Cpi%7D%7B%5Cdisplaystyle+%5Cint_%7B%5Cmathbb%7BM%7D%7D+%7Dtr%28%7BA%7D%5Cwedge+d%7BA%7D%29%5Cbigg%29+exp%5Cbigg%28i+%7B%5Cdisplaystyle+%5Cint%7D+A%5Cbigg%29%3Dexp%28%5Cmathbf%7B%5Cmathcal%7BL%7Dk%7D%5BK%2C+K%27%5D%29+&bg=ffffff&fg=545454&s=0&c=20201002)
 of the curves
of the curves  describes the number of times one curve intersects the surface bounded by the other.
describes the number of times one curve intersects the surface bounded by the other.
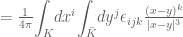
 forming a link
forming a link
![s \in[0,1]](https://s0.wp.com/latex.php?latex=s+%5Cin%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002) ,
,
![[\frac{d\vec{y}(s')}{ds'} \wedge \frac{d\vec{y}(s')}{ds'}]](https://s0.wp.com/latex.php?latex=%C2%A0+%5B%5Cfrac%7Bd%5Cvec%7By%7D%28s%27%29%7D%7Bds%27%7D+%5Cwedge+%5Cfrac%7Bd%5Cvec%7By%7D%28s%27%29%7D%7Bds%27%7D%5D&bg=ffffff&fg=545454&s=0&c=20201002)

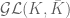 for when the curves coincide. However,
for when the curves coincide. However,  can still always describe the properties of a ribbon with edges
can still always describe the properties of a ribbon with edges  and
and  that self-entangles or knots about its main helical axis
that self-entangles or knots about its main helical axis 
 and
and  flow in two loops
flow in two loops  and
and  then the ‘action-at-a -distance’ formula for the mutual energy is
then the ‘action-at-a -distance’ formula for the mutual energy is
 , with the magnetic field
, with the magnetic field  essentially the ‘helicity’
essentially the ‘helicity’  . Suppose
. Suppose  and let
and let  be curves or knots within domain
be curves or knots within domain  and
and  such that
such that  and
and  . Let
. Let  be a magnetic field defined for all
be a magnetic field defined for all  . The field obeys the Maxwell equations so that
. The field obeys the Maxwell equations so that where
where 
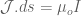
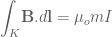 . If we know introduce the vector potential
. If we know introduce the vector potential  then
then  and the Coulomb gauge is
and the Coulomb gauge is 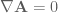 then
then 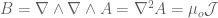 . The solution for the vector potential is
. The solution for the vector potential is

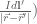
 as the current only has support within the wire. The magnetic field is then
as the current only has support within the wire. The magnetic field is then

 around
around 

 and
and  then (-) it can be expressed as
then (-) it can be expressed as
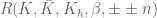 be a (twisted) ribbon with edges
be a (twisted) ribbon with edges 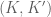 and width
and width 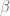 , then if
, then if  is identified with
is identified with  , then the linking number is the sum of twist and writhe about the helical axis
, then the linking number is the sum of twist and writhe about the helical axis  and
and  as
as 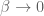

![\mathbf{\mathcal{TW}}(K_{h})=\frac{1}{2\pi}\int_{\mathfrak{S}} ds \frac{d\vec{x}(s)}{ds}.\left[\vec{N}(s)\wedge\frac {d\vec{N}(s)}{ds}\right]/[d\vec{x}(s)/ds]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7B%5Cmathcal%7BTW%7D%7D%28K_%7Bh%7D%29%3D%5Cfrac%7B1%7D%7B2%5Cpi%7D%5Cint_%7B%5Cmathfrak%7BS%7D%7D+ds+%5Cfrac%7Bd%5Cvec%7Bx%7D%28s%29%7D%7Bds%7D.%5Cleft%5B%5Cvec%7BN%7D%28s%29%5Cwedge%5Cfrac+%7Bd%5Cvec%7BN%7D%28s%29%7D%7Bds%7D%5Cright%5D%2F%5Bd%5Cvec%7Bx%7D%28s%29%2Fds%5D+&bg=ffffff&fg=545454&s=0&c=20201002)

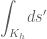

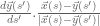
 is the unit vector pointing to
is the unit vector pointing to  and
and  . If
. If  is the normal vector then
is the normal vector then 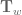 is the total integrated torsion of the single curve
is the total integrated torsion of the single curve 
 be a (2+1)-dimensional manifold and consider an Abelian
be a (2+1)-dimensional manifold and consider an Abelian  Chern-Simons gauge field with cpts.
Chern-Simons gauge field with cpts.  . The basic action is
. The basic action is![S_{CS}[A]=\frac{k}{2} \int_{\mathbb{M}} d^{3}x \epsilon^{\mu\nu\rho}A_{\mu}(x)\partial_{\nu} A_{\mu}(x) = \frac{k}{2}{\displaystyle \int_{\mathbb{M}}} A \wedge dA](https://s0.wp.com/latex.php?latex=%C2%A0+%C2%A0S_%7BCS%7D%5BA%5D%3D%5Cfrac%7Bk%7D%7B2%7D+%5Cint_%7B%5Cmathbb%7BM%7D%7D+d%5E%7B3%7Dx+%5Cepsilon%5E%7B%5Cmu%5Cnu%5Crho%7DA_%7B%5Cmu%7D%28x%29%5Cpartial_%7B%5Cnu%7D+A_%7B%5Cmu%7D%28x%29+%3D+%5Cfrac%7Bk%7D%7B2%7D%7B%5Cdisplaystyle+%5Cint_%7B%5Cmathbb%7BM%7D%7D%7D+A+%C2%A0%5Cwedge+%C2%A0dA%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
 and not
and not  . One defines a product of Wilson loops
. One defines a product of Wilson loops![W[\lbrace q_{i}\rbrace;A]]=\prod_{i=1}^{r} exp\left(iq_{i}\int_{\mathfrak{S}_{i}}A_{\mu}(x)dx^{\mu}\right)\equiv exp\left(iq_{i}\int_{\mathfrak{S}_{i}}A\right)](https://s0.wp.com/latex.php?latex=%C2%A0W%5B%5Clbrace+q_%7Bi%7D%5Crbrace%3BA%5D%5D%3D%5Cprod_%7Bi%3D1%7D%5E%7Br%7D+exp%5Cleft%28iq_%7Bi%7D%5Cint_%7B%5Cmathfrak%7BS%7D_%7Bi%7D%7DA_%7B%5Cmu%7D%28x%29dx%5E%7B%5Cmu%7D%5Cright%29%5Cequiv+exp%5Cleft%28iq_%7Bi%7D%5Cint_%7B%5Cmathfrak%7BS%7D_%7Bi%7D%7DA%5Cright%29%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
 , the trajectories of particles with charges
, the trajectories of particles with charges  , with $i=1…n$. Gauge invariance requires that
, with $i=1…n$. Gauge invariance requires that  are integers (ref Yang.) The vacuum expectation values of the Wilson loops are given by a path integral
are integers (ref Yang.) The vacuum expectation values of the Wilson loops are given by a path integral![\left\langle W[\lbrace q_{i}\rbrace;A]]\right\rangle =\frac{\left\langle\psi_{o}\|W[\lbrace q_{i}\rbrace;A]]\|\psi_{o}\right\rangle}{\left\langle\psi_{o}|\psi_{o}|\right\rangle}](https://s0.wp.com/latex.php?latex=%C2%A0%5Cleft%5Clangle+W%5B%5Clbrace+q_%7Bi%7D%5Crbrace%3BA%5D%5D%5Cright%5Crangle+%3D%5Cfrac%7B%5Cleft%5Clangle%5Cpsi_%7Bo%7D%5C%7CW%5B%5Clbrace+q_%7Bi%7D%5Crbrace%3BA%5D%5D%5C%7C%5Cpsi_%7Bo%7D%5Cright%5Crangle%7D%7B%5Cleft%5Clangle%5Cpsi_%7Bo%7D%7C%5Cpsi_%7Bo%7D%7C%5Cright%5Crangle%7D&bg=ffffff&fg=545454&s=0&c=20201002)
![= \frac{{\displaystyle\int}\mathcal{D}A W[\lbrace q_{i}\rbrace ;A]]\exp(iS_{CS}[A])}{{\displaystyle\int} \mathcal{D}A exp(iS_{CS}[A])}](https://s0.wp.com/latex.php?latex=%3D+%5Cfrac%7B%7B%5Cdisplaystyle%5Cint%7D%5Cmathcal%7BD%7DA+W%5B%5Clbrace+q_%7Bi%7D%5Crbrace+%3BA%5D%5D%5Cexp%28iS_%7BCS%7D%5BA%5D%29%7D%7B%7B%5Cdisplaystyle%5Cint%7D+%5Cmathcal%7BD%7DA+exp%28iS_%7BCS%7D%5BA%5D%29%7D+&bg=ffffff&fg=545454&s=0&c=20201002)
 is the vacuum state and
is the vacuum state and  is the functional integral over the gauge field. The calculation can be done exactly (refs) and is
is the functional integral over the gauge field. The calculation can be done exactly (refs) and is![\langle W[q_{i} ; A] \rangle = exp\bigg(\frac{i}{2k}](https://s0.wp.com/latex.php?latex=%C2%A0+%5Clangle+W%5Bq_%7Bi%7D+%3B+A%5D+%C2%A0%5Crangle+%C2%A0%3D+%C2%A0exp%5Cbigg%28%5Cfrac%7Bi%7D%7B2k%7D%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)

 is the linking number. The non-abelian C-S theory can also be solved and connects with the Jones polynomial for knot theory.
is the linking number. The non-abelian C-S theory can also be solved and connects with the Jones polynomial for knot theory.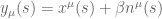 , then the self intersection is avoided since every curve
, then the self intersection is avoided since every curve 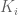 is smeared out into thin ribbon of width
is smeared out into thin ribbon of width 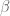 with edges
with edges  and
and  (ref Witten.) If
(ref Witten.) If  then
then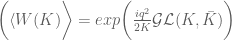
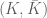 . This is useful from the point of view of quantum computing where the ribbon edges can represent worldlines of anyons and braiding is achieved by twisting the ribbon. A twist in the ribbon gives a linking of the worldlines and is registered within the Wilson-loop expected values as a phase shift. For example, if a ribbon
. This is useful from the point of view of quantum computing where the ribbon edges can represent worldlines of anyons and braiding is achieved by twisting the ribbon. A twist in the ribbon gives a linking of the worldlines and is registered within the Wilson-loop expected values as a phase shift. For example, if a ribbon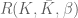 is twisted by
is twisted by  then
then  . Then
. Then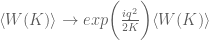
 . Then a point
. Then a point 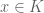 and a point
and a point  can experience a Coulomb force. The configuration of the knot may the evolve to decrease its electrostatic energy to a minima. Charged polymers in a solution. Knot energy functionals for a single knot, in the mathematical sense, were considered in relation to an electrostatic anology with a modified Coulomb potential (refs.)
can experience a Coulomb force. The configuration of the knot may the evolve to decrease its electrostatic energy to a minima. Charged polymers in a solution. Knot energy functionals for a single knot, in the mathematical sense, were considered in relation to an electrostatic anology with a modified Coulomb potential (refs.) be a charged knot and let
be a charged knot and let 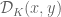 be the shorter arc length between
be the shorter arc length between  and
and  . The unregulated knot energy functional for
. The unregulated knot energy functional for 
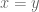 . To regulate
. To regulate  , the following are defined
, the following are defined
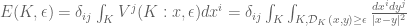


 is the “voltage” at x when the subarc
is the “voltage” at x when the subarc 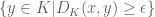 is charged. The regulated knot energy functional of O’Hara is then (ref)
is charged. The regulated knot energy functional of O’Hara is then (ref)
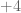 term can be dropped and for
term can be dropped and for 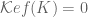 .
.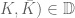 Let
Let  and let
and let 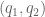 be a pair of charges at
be a pair of charges at 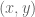 . The Coulomb law is then
. The Coulomb law is then
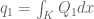 and
and  , where
, where  are charge densities. This gives
are charge densities. This gives
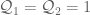 we can define a non-regulated knot energy functional of the form
we can define a non-regulated knot energy functional of the form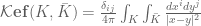

 denotes the Einstein tensor,
denotes the Einstein tensor,  is the usual Newton constant and the scalar field
is the usual Newton constant and the scalar field  is a position dependent Newton constant.
is a position dependent Newton constant.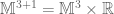 is
is![S_{EH}[g,G]=\frac{1}{16\pi G}{\displaystyle \int_{\mathbb{M}^{3+1}}} d^{4}x\sqrt{-g}\mathbf{R}](https://s0.wp.com/latex.php?latex=%C2%A0%C2%A0S_%7BEH%7D%5Bg%2CG%5D%3D%5Cfrac%7B1%7D%7B16%5Cpi+G%7D%7B%5Cdisplaystyle+%5Cint_%7B%5Cmathbb%7BM%7D%5E%7B3%2B1%7D%7D%7D+d%5E%7B4%7Dx%5Csqrt%7B-g%7D%5Cmathbf%7BR%7D+&bg=ffffff&fg=545454&s=0&c=20201002)
 , so that
, so that![S_{tot}=\frac{1}{16\pi G} {\displaystyle \int_{\mathbb{M}^{3+1}}}d^{4}x\sqrt{-g}\mathbf{R}+S_{M}[g]](https://s0.wp.com/latex.php?latex=%C2%A0S_%7Btot%7D%3D%5Cfrac%7B1%7D%7B16%5Cpi+G%7D+%7B%5Cdisplaystyle+%5Cint_%7B%5Cmathbb%7BM%7D%5E%7B3%2B1%7D%7D%7Dd%5E%7B4%7Dx%5Csqrt%7B-g%7D%5Cmathbf%7BR%7D%2BS_%7BM%7D%5Bg%5D%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{T}_{\mu\nu}=\frac{2}{\sqrt{-g}}\frac{\delta S_{M}[g]}{\delta g_{\mu\nu}}](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BT%7D_%7B%5Cmu%5Cnu%7D%3D%5Cfrac%7B2%7D%7B%5Csqrt%7B-g%7D%7D%5Cfrac%7B%5Cdelta+S_%7BM%7D%5Bg%5D%7D%7B%5Cdelta+g_%7B%5Cmu%5Cnu%7D%7D+&bg=ffffff&fg=545454&s=0&c=20201002) .
.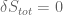 gives the usual Einstein field equations
gives the usual Einstein field equations
![S_{EH}[g,G]=\frac{1}{16\pi}{\displaystyle \int_{\mathbb{M}}^{3+1}} d^{4}x \sqrt{-g}\frac{\mathbf{R}}{\mathcal{G}(x)}+S_{M}+S_{\Phi}](https://s0.wp.com/latex.php?latex=%C2%A0S_%7BEH%7D%5Bg%2CG%5D%3D%5Cfrac%7B1%7D%7B16%5Cpi%7D%7B%5Cdisplaystyle+%5Cint_%7B%5Cmathbb%7BM%7D%7D%5E%7B3%2B1%7D%7D+d%5E%7B4%7Dx+%5Csqrt%7B-g%7D%5Cfrac%7B%5Cmathbf%7BR%7D%7D%7B%5Cmathcal%7BG%7D%28x%29%7D%2BS_%7BM%7D%2BS_%7B%5CPhi%7D+&bg=ffffff&fg=545454&s=0&c=20201002)
 is now a source for the scalar field
is now a source for the scalar field  was introduced as the inverse of a position-dependent Newton constant so that
was introduced as the inverse of a position-dependent Newton constant so that  . The action for the theory is
. The action for the theory is


 is the source tensor arising from the matter while
is the source tensor arising from the matter while  is the source tensor for the field
is the source tensor for the field  (refs.)
(refs.)![\mathbf{T}_{\mu\nu}^{BD}=\frac{\omega}{8\pi \phi}[\nabla_{\mu}\phi\nabla_{\nu}\phi-\frac{1}{2}g_{\mu\nu}\nabla_{\alpha}\phi \nabla ^{\alpha}\phi]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BT%7D_%7B%5Cmu%5Cnu%7D%5E%7BBD%7D%3D%5Cfrac%7B%5Comega%7D%7B8%5Cpi+%5Cphi%7D%5B%5Cnabla_%7B%5Cmu%7D%5Cphi%5Cnabla_%7B%5Cnu%7D%5Cphi-%5Cfrac%7B1%7D%7B2%7Dg_%7B%5Cmu%5Cnu%7D%5Cnabla_%7B%5Calpha%7D%5Cphi+%5Cnabla+%5E%7B%5Calpha%7D%5Cphi%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
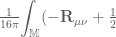
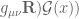




 )
)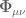 is the source term for the scalar field
is the source term for the scalar field 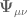 is the tensor that arises from the position dependence of
is the tensor that arises from the position dependence of 


 is
is
![\widehat{\mathbf{\Psi}}_{\mu\nu}=\mathcal{G}(x)^{-2}[2\nabla_{\mu}\mathcal{G}(x)\nabla_{\nu}\mathcal{G}(x) -\mathcal{G}(x)\nabla_{\mu}\nabla_{\nu}\mathcal{G}(x)-2g_{\mu\nu} \nabla_{\mu}\mathcal{G}\nabla^{\mu}\mathcal{G}(x)-\mathcal{G}(x)\square\mathcal{G}(x)]](https://s0.wp.com/latex.php?latex=%C2%A0%C2%A0%5Cwidehat%7B%5Cmathbf%7B%5CPsi%7D%7D_%7B%5Cmu%5Cnu%7D%3D%5Cmathcal%7BG%7D%28x%29%5E%7B-2%7D%5B2%5Cnabla_%7B%5Cmu%7D%5Cmathcal%7BG%7D%28x%29%5Cnabla_%7B%5Cnu%7D%5Cmathcal%7BG%7D%28x%29+-%5Cmathcal%7BG%7D%28x%29%5Cnabla_%7B%5Cmu%7D%5Cnabla_%7B%5Cnu%7D%5Cmathcal%7BG%7D%28x%29-2g_%7B%5Cmu%5Cnu%7D+%5Cnabla_%7B%5Cmu%7D%5Cmathcal%7BG%7D%5Cnabla%5E%7B%5Cmu%7D%5Cmathcal%7BG%7D%28x%29-%5Cmathcal%7BG%7D%28x%29%5Csquare%5Cmathcal%7BG%7D%28x%29%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
![\widehat{\mathbf{\Psi}}_{\mu}^{\mu}=\frac{3}{\mathcal{G}^{3}(x)}[\mathcal{G}(x)\square \mathcal{G}(x)-2\nabla_{\mu}\nabla^{\mu}\mathcal{G}]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cwidehat%7B%5Cmathbf%7B%5CPsi%7D%7D_%7B%5Cmu%7D%5E%7B%5Cmu%7D%3D%5Cfrac%7B3%7D%7B%5Cmathcal%7BG%7D%5E%7B3%7D%28x%29%7D%5B%5Cmathcal%7BG%7D%28x%29%5Csquare+%5Cmathcal%7BG%7D%28x%29-2%5Cnabla_%7B%5Cmu%7D%5Cnabla%5E%7B%5Cmu%7D%5Cmathcal%7BG%7D%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
![\nabla^{\mu}\widehat{\mathbf{\Psi}}_{\mu\nu}=\frac{1}{\mathcal{G}(x)}\nabla^{\mu} \mathcal{G}(x)(\mathbf{\Psi}_{\mu\nu}-\mathbf{R}_{\mu\nu}]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cnabla%5E%7B%5Cmu%7D%5Cwidehat%7B%5Cmathbf%7B%5CPsi%7D%7D_%7B%5Cmu%5Cnu%7D%3D%5Cfrac%7B1%7D%7B%5Cmathcal%7BG%7D%28x%29%7D%5Cnabla%5E%7B%5Cmu%7D+%5Cmathcal%7BG%7D%28x%29%28%5Cmathbf%7B%5CPsi%7D_%7B%5Cmu%5Cnu%7D-%5Cmathbf%7BR%7D_%7B%5Cmu%5Cnu%7D%5D%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)

![\frac{3}{2}\frac{\nabla_{\nu}\mathcal{G}(x)}{\mathcal{G}(x)^{2}}[\mathcal{G}(x)\square \mathcal{G}(x)-2(\nabla_{\mu}\mathcal{G}\nabla^{\mu}\mathcal{G}(x)))]+\nabla^{\mu} \widehat{\Phi}_{\mu\nu} -\frac{\nabla^{\mu}\mathcal{G}(x)}{\mathcal{G}(x)}\widehat{\Phi}_{\mu\nu}+4\pi \mathbf{T}\nabla_{\nu}\mathcal{G}(x)=0](https://s0.wp.com/latex.php?latex=%C2%A0%5Cfrac%7B3%7D%7B2%7D%5Cfrac%7B%5Cnabla_%7B%5Cnu%7D%5Cmathcal%7BG%7D%28x%29%7D%7B%5Cmathcal%7BG%7D%28x%29%5E%7B2%7D%7D%5B%5Cmathcal%7BG%7D%28x%29%5Csquare+%5Cmathcal%7BG%7D%28x%29-2%28%5Cnabla_%7B%5Cmu%7D%5Cmathcal%7BG%7D%5Cnabla%5E%7B%5Cmu%7D%5Cmathcal%7BG%7D%28x%29%29%29%5D%2B%5Cnabla%5E%7B%5Cmu%7D++%5Cwidehat%7B%5CPhi%7D_%7B%5Cmu%5Cnu%7D+-%5Cfrac%7B%5Cnabla%5E%7B%5Cmu%7D%5Cmathcal%7BG%7D%28x%29%7D%7B%5Cmathcal%7BG%7D%28x%29%7D%5Cwidehat%7B%5CPhi%7D_%7B%5Cmu%5Cnu%7D%2B4%5Cpi+%5Cmathbf%7BT%7D%5Cnabla_%7B%5Cnu%7D%5Cmathcal%7BG%7D%28x%29%3D0%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
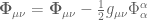 and
and  . When
. When  , then the energy-momentum tensor is traceless giving
, then the energy-momentum tensor is traceless giving![\frac{3}{2}\frac{\nabla_{\nu}\mathcal{G}}{\mathcal{G}(x)^{2}}[\mathcal{G}(x)\square \mathcal{G}(x)-2(\nabla_{\mu}\mathcal{G}(x)\nabla^{\mu}\mathcal{G}(x)))]+\nabla^{\mu}\widehat{\Phi}_{\mu\nu} -\frac{\nabla^{\mu}\mathcal{G}9x)}{\mathcal{G}}\widehat{\Phi}_{\mu\nu}=0](https://s0.wp.com/latex.php?latex=%C2%A0%5Cfrac%7B3%7D%7B2%7D%5Cfrac%7B%5Cnabla_%7B%5Cnu%7D%5Cmathcal%7BG%7D%7D%7B%5Cmathcal%7BG%7D%28x%29%5E%7B2%7D%7D%5B%5Cmathcal%7BG%7D%28x%29%5Csquare+%5Cmathcal%7BG%7D%28x%29-2%28%5Cnabla_%7B%5Cmu%7D%5Cmathcal%7BG%7D%28x%29%5Cnabla%5E%7B%5Cmu%7D%5Cmathcal%7BG%7D%28x%29%29%29%5D%2B%5Cnabla%5E%7B%5Cmu%7D%5Cwidehat%7B%5CPhi%7D_%7B%5Cmu%5Cnu%7D+-%5Cfrac%7B%5Cnabla%5E%7B%5Cmu%7D%5Cmathcal%7BG%7D9x%29%7D%7B%5Cmathcal%7BG%7D%7D%5Cwidehat%7B%5CPhi%7D_%7B%5Cmu%5Cnu%7D%3D0+&bg=ffffff&fg=545454&s=0&c=20201002)
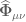 which solves this equation has the form
which solves this equation has the form![\mathbf{\Phi}_{\mu\nu}^{BD}= \bigg(-\frac{3}{2}\bigg)\frac{1}{8\pi \mathcal{G}(x)^{3}}[\nabla_{\mu}\mathcal{G}(x)\nabla_{\nu}\mathcal{G}(x)-\frac{1}{2}g_{\mu\nu}\nabla_{\mu} \mathcal{G}(x)\nabla^{\mu}G(x)]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7B%5CPhi%7D_%7B%5Cmu%5Cnu%7D%5E%7BBD%7D%3D+%5Cbigg%28-%5Cfrac%7B3%7D%7B2%7D%5Cbigg%29%5Cfrac%7B1%7D%7B8%5Cpi+%5Cmathcal%7BG%7D%28x%29%5E%7B3%7D%7D%5B%5Cnabla_%7B%5Cmu%7D%5Cmathcal%7BG%7D%28x%29%5Cnabla_%7B%5Cnu%7D%5Cmathcal%7BG%7D%28x%29-%5Cfrac%7B1%7D%7B2%7Dg_%7B%5Cmu%5Cnu%7D%5Cnabla_%7B%5Cmu%7D+%5Cmathcal%7BG%7D%28x%29%5Cnabla%5E%7B%5Cmu%7DG%28x%29%5D%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
 and
and 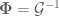 , this is then equivalent to the original Brans-Dicke source tensor (-) The action
, this is then equivalent to the original Brans-Dicke source tensor (-) The action 
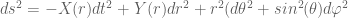
 we require that
we require that  so that
so that  and so G can vary with the radial coordinate
and so G can vary with the radial coordinate  only. The radial derivatives will be denoted
only. The radial derivatives will be denoted  and
and  . It will be instructive to initially formulate the full generic modified field equations on this metric, and then solve for the specific case when there is no matter and no cosmological constant term. This will illucidate how the solution of the modified vacuum equations compares to the Standard Schwarzschild vacuum solution and the interior Schwarzschild solution. The full modified Einstein equations are
. It will be instructive to initially formulate the full generic modified field equations on this metric, and then solve for the specific case when there is no matter and no cosmological constant term. This will illucidate how the solution of the modified vacuum equations compares to the Standard Schwarzschild vacuum solution and the interior Schwarzschild solution. The full modified Einstein equations are


 and
and  . The source tensor for fluid system in hydrostatic equilibrium has the usual form
. The source tensor for fluid system in hydrostatic equilibrium has the usual form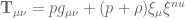
 so that
so that ![\mathbf{T}_{\mu\nu}=diag[-\rho(r),p(r),p(r),p(r)]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BT%7D_%7B%5Cmu%5Cnu%7D%3Ddiag%5B-%5Crho%28r%29%2Cp%28r%29%2Cp%28r%29%2Cp%28r%29%5D&bg=ffffff&fg=545454&s=0&c=20201002) . The conservation equation arising from the Bianchi identities is
. The conservation equation arising from the Bianchi identities is  and leads to the condition
and leads to the condition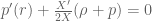
![\mathbf{\Psi}_{\mu\nu}=\frac{\widehat{\mathbf{\Psi}}_{\mu\nu}}{8\pi \mathcal{G}}=diag[-\mathcal{D}(r),\mathcal{P}(r),\mathcal{P}_{a}(r),\mathcal{P}_{a}(r)]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7B%5CPsi%7D_%7B%5Cmu%5Cnu%7D%3D%5Cfrac%7B%5Cwidehat%7B%5Cmathbf%7B%5CPsi%7D%7D_%7B%5Cmu%5Cnu%7D%7D%7B8%5Cpi+%5Cmathcal%7BG%7D%7D%3Ddiag%5B-%5Cmathcal%7BD%7D%28r%29%2C%5Cmathcal%7BP%7D%28r%29%2C%5Cmathcal%7BP%7D_%7Ba%7D%28r%29%2C%5Cmathcal%7BP%7D_%7Ba%7D%28r%29%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
 is an energy density induced by the position-dependence of Newton’s constant, and
is an energy density induced by the position-dependence of Newton’s constant, and  is the associated radial pressure and
is the associated radial pressure and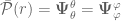 , are the angular or tangential pressures.
, are the angular or tangential pressures.




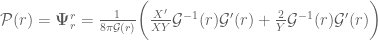
![\bar{\mathcal{P}}(r)=\mathbf{\Psi}_{\theta}^{\theta}=\mathbf{\Psi}_{\varphi}^{\varphi} =\frac{1}{8\pi \mathcal{G}(r)}\bigg(\frac{1}{rY}\mathcal{G}^{-1}(r)\mathcal{G}^{\prime}(r) -\frac{Y^{\prime}}{2Y^{2}}G^{-1}(r)\mathcal{G}^{\prime}(r)\nonumber\\[0.1in]+ \frac{X^{\prime}}{2XY}\mathcal{G}^{-1}(r)G^{\prime}(r)-\frac{2}{Y}\mathcal{G}^{-2}(r)\mathcal{G}^{\prime}(r) \mathcal{G}^{\prime}(r) -\frac{1}{Y}\mathcal{G}^{-1}(r)\mathcal{G}^{\prime\prime}(r)\bigg)](https://s0.wp.com/latex.php?latex=%C2%A0+%5Cbar%7B%5Cmathcal%7BP%7D%7D%28r%29%3D%5Cmathbf%7B%5CPsi%7D_%7B%5Ctheta%7D%5E%7B%5Ctheta%7D%3D%5Cmathbf%7B%5CPsi%7D_%7B%5Cvarphi%7D%5E%7B%5Cvarphi%7D+%3D%5Cfrac%7B1%7D%7B8%5Cpi+%5Cmathcal%7BG%7D%28r%29%7D%5Cbigg%28%5Cfrac%7B1%7D%7BrY%7D%5Cmathcal%7BG%7D%5E%7B-1%7D%28r%29%5Cmathcal%7BG%7D%5E%7B%5Cprime%7D%28r%29+-%5Cfrac%7BY%5E%7B%5Cprime%7D%7D%7B2Y%5E%7B2%7D%7DG%5E%7B-1%7D%28r%29%5Cmathcal%7BG%7D%5E%7B%5Cprime%7D%28r%29%5Cnonumber%5C%5C%5B0.1in%5D%2B+%5Cfrac%7BX%5E%7B%5Cprime%7D%7D%7B2XY%7D%5Cmathcal%7BG%7D%5E%7B-1%7D%28r%29G%5E%7B%5Cprime%7D%28r%29-%5Cfrac%7B2%7D%7BY%7D%5Cmathcal%7BG%7D%5E%7B-2%7D%28r%29%5Cmathcal%7BG%7D%5E%7B%5Cprime%7D%28r%29+%5Cmathcal%7BG%7D%5E%7B%5Cprime%7D%28r%29+-%5Cfrac%7B1%7D%7BY%7D%5Cmathcal%7BG%7D%5E%7B-1%7D%28r%29%5Cmathcal%7BG%7D%5E%7B%5Cprime%5Cprime%7D%28r%29%5Cbigg%29+&bg=ffffff&fg=545454&s=0&c=20201002)
 source tensor will be left arbitrary for the moment, but it is sufficient that it has same diagonalised form
source tensor will be left arbitrary for the moment, but it is sufficient that it has same diagonalised form![\mathbf{\Phi}_{\mu}^{\nu}=diag[-\mathscr{D}(r),\mathscr{P}(r),\bar{\mathcal{P}}(r),\bar{\mathcal{P}}(r)]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7B%5CPhi%7D_%7B%5Cmu%7D%5E%7B%5Cnu%7D%3Ddiag%5B-%5Cmathscr%7BD%7D%28r%29%2C%5Cmathscr%7BP%7D%28r%29%2C%5Cbar%7B%5Cmathcal%7BP%7D%7D%28r%29%2C%5Cbar%7B%5Cmathcal%7BP%7D%7D%28r%29%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
 or vacuum ‘dark energy’ with no spatial dependence such that
or vacuum ‘dark energy’ with no spatial dependence such that ![\mathbf{\Theta}_{\mu}^{\nu}=diag[-\rho_{v},p_{v},p_{v},p_{v}]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7B%5CTheta%7D_%7B%5Cmu%7D%5E%7B%5Cnu%7D%3Ddiag%5B-%5Crho_%7Bv%7D%2Cp_%7Bv%7D%2Cp_%7Bv%7D%2Cp_%7Bv%7D%5D&bg=ffffff&fg=545454&s=0&c=20201002) with
with  and
and  . The total source tensor is then
. The total source tensor is then![\mathbf{T}_{\mu}^{\nu}=diag[-D(r),P(r),\bar{P}(r),\bar{P}(r)]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BT%7D_%7B%5Cmu%7D%5E%7B%5Cnu%7D%3Ddiag%5B-D%28r%29%2CP%28r%29%2C%5Cbar%7BP%7D%28r%29%2C%5Cbar%7BP%7D%28r%29%5D%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
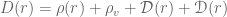


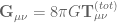
 so that the full field equations are
so that the full field equations are![\mathbf{G}_{t}^{t}=-8\pi \mathcal{G} D(r)=-8\pi \mathcal{G}[\rho(r)+\rho_{v}+\mathcal{D}(r)+\mathscr{D}(r)]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BG%7D_%7Bt%7D%5E%7Bt%7D%3D-8%5Cpi+%5Cmathcal%7BG%7D+D%28r%29%3D-8%5Cpi+%5Cmathcal%7BG%7D%5B%5Crho%28r%29%2B%5Crho_%7Bv%7D%2B%5Cmathcal%7BD%7D%28r%29%2B%5Cmathscr%7BD%7D%28r%29%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{G}_{r}^{r}=~8\pi\mathcal{G} P(r)=~8\pi G[p(r)+p_{v}+\mathcal{P}(r)+\mathscr{P}(r)]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BG%7D_%7Br%7D%5E%7Br%7D%3D%7E8%5Cpi%5Cmathcal%7BG%7D+P%28r%29%3D%7E8%5Cpi+G%5Bp%28r%29%2Bp_%7Bv%7D%2B%5Cmathcal%7BP%7D%28r%29%2B%5Cmathscr%7BP%7D%28r%29%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{G}_{\theta}^{\theta}=\mathbf{G}_{\varphi}^{\varphi}=8\pi P_{a}(r)=8\pi \mathcal{G}[p(r)+p_{v}+\mathcal{P}_{a}(r)+\bar{\mathcal{P}}(r)]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BG%7D_%7B%5Ctheta%7D%5E%7B%5Ctheta%7D%3D%5Cmathbf%7BG%7D_%7B%5Cvarphi%7D%5E%7B%5Cvarphi%7D%3D8%5Cpi+P_%7Ba%7D%28r%29%3D8%5Cpi+%5Cmathcal%7BG%7D%5Bp%28r%29%2Bp_%7Bv%7D%2B%5Cmathcal%7BP%7D_%7Ba%7D%28r%29%2B%5Cbar%7B%5Cmathcal%7BP%7D%7D%28r%29%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
 and
and 


![\mathbf{G}_{\theta}^{theta}=\mathbf{G}_{\varphi}^{\varphi}= -\frac{Y^{\prime}}{2rY^{2}}+\frac{X^{\prime}}{2r XY}-\frac{X^{\prime} Y^{\prime}}{4B^{2}X}-\frac{(X^{\prime})^{2}}{4YX^{2}}+ \frac{\partial_{rr}X^{ \prime\prime}}{2XY}=8\pi \mathcal{G} [p(r)+p_{v}+\mathcal{P}_{a}+\bar{\mathscr{P}}]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BG%7D_%7B%5Ctheta%7D%5E%7Btheta%7D%3D%5Cmathbf%7BG%7D_%7B%5Cvarphi%7D%5E%7B%5Cvarphi%7D%3D+-%5Cfrac%7BY%5E%7B%5Cprime%7D%7D%7B2rY%5E%7B2%7D%7D%2B%5Cfrac%7BX%5E%7B%5Cprime%7D%7D%7B2r+XY%7D-%5Cfrac%7BX%5E%7B%5Cprime%7D+Y%5E%7B%5Cprime%7D%7D%7B4B%5E%7B2%7DX%7D-%5Cfrac%7B%28X%5E%7B%5Cprime%7D%29%5E%7B2%7D%7D%7B4YX%5E%7B2%7D%7D%2B+%5Cfrac%7B%5Cpartial_%7Brr%7DX%5E%7B+%5Cprime%5Cprime%7D%7D%7B2XY%7D%3D8%5Cpi+%5Cmathcal%7BG%7D+%5Bp%28r%29%2Bp_%7Bv%7D%2B%5Cmathcal%7BP%7D_%7Ba%7D%2B%5Cbar%7B%5Cmathscr%7BP%7D%7D%5D+&bg=ffffff&fg=545454&s=0&c=20201002)

 and the existence of stochastic integrals, Wilson lines can be constructed.
and the existence of stochastic integrals, Wilson lines can be constructed. be an open string/knot or smooth curve in the simply connected region
be an open string/knot or smooth curve in the simply connected region 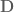 with Euclidean coordinates
with Euclidean coordinates  , where
, where ![s \in [0,1]](https://s0.wp.com/latex.php?latex=s+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002) and with ends
and with ends  and
and  . Now let
. Now let 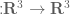 be a smooth non-random vector field defined for all
be a smooth non-random vector field defined for all 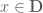 . Then the classical Wilson-line holonomy is
. Then the classical Wilson-line holonomy is![W[K]=\mathcal{P} exp\bigg(\mu{\displaystyle \int_{0}^{s}}d\bar{s}{X}_{i}(x(\bar{s})) \frac{dx^{i}}{d\bar{s}}d\bar{s}\bigg)= \vec{\mathcal{P}} exp\bigg ({\displaystyle \int_{K}}{X}_{i}(x)dx^{i} \bigg)](https://s0.wp.com/latex.php?latex=%C2%A0W%5BK%5D%3D%5Cmathcal%7BP%7D+exp%5Cbigg%28%5Cmu%7B%5Cdisplaystyle+%5Cint_%7B0%7D%5E%7Bs%7D%7Dd%5Cbar%7Bs%7D%7BX%7D_%7Bi%7D%28x%28%5Cbar%7Bs%7D%29%29%C2%A0%5Cfrac%7Bdx%5E%7Bi%7D%7D%7Bd%5Cbar%7Bs%7D%7Dd%5Cbar%7Bs%7D%5Cbigg%29%3D%C2%A0%5Cvec%7B%5Cmathcal%7BP%7D%7D+exp%5Cbigg+%28%7B%5Cdisplaystyle+%5Cint_%7BK%7D%7D%7BX%7D_%7Bi%7D%28x%29dx%5E%7Bi%7D+%5Cbigg%29+&bg=ffffff&fg=545454&s=0&c=20201002)
![W[K]=\vec{\mathcal{P}} exp\bigg({\displaystyle \oint_{\gamma}}X_{i}(x)dx^{i}\bigg)](https://s0.wp.com/latex.php?latex=W%5BK%5D%3D%5Cvec%7B%5Cmathcal%7BP%7D%7D+exp%5Cbigg%28%7B%5Cdisplaystyle+%5Coint_%7B%5Cgamma%7D%7DX_%7Bi%7D%28x%29dx%5E%7Bi%7D%5Cbigg%29&bg=ffffff&fg=545454&s=0&c=20201002)
 with
with ![W:[0,1]\rightarrow \mathbb{R}^{+}](https://s0.wp.com/latex.php?latex=W%3A%5B0%2C1%5D%5Crightarrow+%5Cmathbb%7BR%7D%5E%7B%2B%7D&bg=ffffff&fg=545454&s=0&c=20201002) be a smooth differentiable function on
be a smooth differentiable function on ![L[K]={\displaystyle \int_{K}}{X}_{i}(x)dx^{i}](https://s0.wp.com/latex.php?latex=L%5BK%5D%3D%7B%5Cdisplaystyle+%5Cint_%7BK%7D%7D%7BX%7D_%7Bi%7D%28x%29dx%5E%7Bi%7D&bg=ffffff&fg=545454&s=0&c=20201002) , define a second integral
, define a second integral![\Psi(K,W(s))={\displaystyle \int_{K}}{X}_{i}(x)W[s]dx^{i} ={\displaystyle \int_{0}^{s}}d\bar{s}{X}_{i}(x(\bar{s}))\frac{dx^{i}(\bar{s})}{d\bar{s}} {W}(\bar{s})](https://s0.wp.com/latex.php?latex=%5CPsi%28K%2CW%28s%29%29%3D%7B%5Cdisplaystyle+%5Cint_%7BK%7D%7D%7BX%7D_%7Bi%7D%28x%29W%5Bs%5Ddx%5E%7Bi%7D+%3D%7B%5Cdisplaystyle+%5Cint_%7B0%7D%5E%7Bs%7D%7Dd%5Cbar%7Bs%7D%7BX%7D_%7Bi%7D%28x%28%5Cbar%7Bs%7D%29%29%5Cfrac%7Bdx%5E%7Bi%7D%28%5Cbar%7Bs%7D%29%7D%7Bd%5Cbar%7Bs%7D%7D+%7BW%7D%28%5Cbar%7Bs%7D%29+&bg=ffffff&fg=545454&s=0&c=20201002)
![{\displaystyle \frac{d\Psi(K,W[s])}{ds}=X_{i}(x(s))\frac{dx^{i}(s)}{ds}W[s]}](https://s0.wp.com/latex.php?latex=%C2%A0%7B%5Cdisplaystyle+%5Cfrac%7Bd%5CPsi%28K%2CW%5Bs%5D%29%7D%7Bds%7D%3DX_%7Bi%7D%28x%28s%29%29%5Cfrac%7Bdx%5E%7Bi%7D%28s%29%7D%7Bds%7DW%5Bs%5D%7D+&bg=ffffff&fg=545454&s=0&c=20201002)
![\Psi(K, W[s])=W[s]](https://s0.wp.com/latex.php?latex=%5CPsi%28K%2C+W%5Bs%5D%29%3DW%5Bs%5D&bg=ffffff&fg=545454&s=0&c=20201002) then
then![{\displaystyle \frac{dW(s)]}{ds}=X_{i}(x(s))\frac{dx^{i}(s)}{ds}W(s)}](https://s0.wp.com/latex.php?latex=%C2%A0%7B%5Cdisplaystyle+%5Cfrac%7BdW%28s%29%5D%7D%7Bds%7D%3DX_%7Bi%7D%28x%28s%29%29%5Cfrac%7Bdx%5E%7Bi%7D%28s%29%7D%7Bds%7DW%28s%29%7D+&bg=ffffff&fg=545454&s=0&c=20201002)
![W(s)=W(0)+{\displaystyle \int_{0}^{s}} ds_{1} X_{i}(x(s_{1}))\frac{dx^{i}(s)}{ds_{1}}W[s_{1}]](https://s0.wp.com/latex.php?latex=%C2%A0+W%28s%29%3DW%280%29%2B%7B%5Cdisplaystyle+%5Cint_%7B0%7D%5E%7Bs%7D%7D+ds_%7B1%7D+X_%7Bi%7D%28x%28s_%7B1%7D%29%29%5Cfrac%7Bdx%5E%7Bi%7D%28s%29%7D%7Bds_%7B1%7D%7DW%5Bs_%7B1%7D%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
![W[s]](https://s0.wp.com/latex.php?latex=W%5Bs%5D&bg=ffffff&fg=545454&s=0&c=20201002) along the curve
along the curve ![W[s]=W[0]](https://s0.wp.com/latex.php?latex=%C2%A0W%5Bs%5D%3DW%5B0%5D&bg=ffffff&fg=545454&s=0&c=20201002)
![+\int_{0}^{s}ds_{1}{X}_{i}(x(s_{1}))\frac{dx^{i}(s)}{ds}\bigg( W[0]+{\displaystyle \int_{0}^{s_{1}}}ds_{2}{X}_{i}(x(s_{2}))\frac{dx^{i}(s_{2})}{ds_{2}} W[s_{2}]\bigg)](https://s0.wp.com/latex.php?latex=%2B%5Cint_%7B0%7D%5E%7Bs%7Dds_%7B1%7D%7BX%7D_%7Bi%7D%28x%28s_%7B1%7D%29%29%5Cfrac%7Bdx%5E%7Bi%7D%28s%29%7D%7Bds%7D%5Cbigg%28+W%5B0%5D%2B%7B%5Cdisplaystyle+%5Cint_%7B0%7D%5E%7Bs_%7B1%7D%7D%7Dds_%7B2%7D%7BX%7D_%7Bi%7D%28x%28s_%7B2%7D%29%29%5Cfrac%7Bdx%5E%7Bi%7D%28s_%7B2%7D%29%7D%7Bds_%7B2%7D%7D%C2%A0W%5Bs_%7B2%7D%5D%5Cbigg%29+&bg=ffffff&fg=545454&s=0&c=20201002)
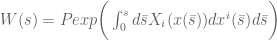

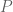 is a ‘normal-ordering’ operator. This is then a classical Wilson-line operator in
is a ‘normal-ordering’ operator. This is then a classical Wilson-line operator in ![W[K]=\vec{\mathcal{P}} exp\bigg(\mu{\displaystyle \int_{0}^{s}}d\bar{s}X_{i}(x(\bar{s}))\frac{dx^{i}(\bar{s})}{d\bar{s}}\bigg)= \vec{\mathcal{P}} exp\bigg({\displaystyle \int_{K}}{X}_{i}(x)dx^{i}\bigg)](https://s0.wp.com/latex.php?latex=%C2%A0W%5BK%5D%3D%5Cvec%7B%5Cmathcal%7BP%7D%7D+exp%5Cbigg%28%5Cmu%7B%5Cdisplaystyle+%5Cint_%7B0%7D%5E%7Bs%7D%7Dd%5Cbar%7Bs%7DX_%7Bi%7D%28x%28%5Cbar%7Bs%7D%29%29%5Cfrac%7Bdx%5E%7Bi%7D%28%5Cbar%7Bs%7D%29%7D%7Bd%5Cbar%7Bs%7D%7D%5Cbigg%29%3D%C2%A0%5Cvec%7B%5Cmathcal%7BP%7D%7D+exp%5Cbigg%28%7B%5Cdisplaystyle+%5Cint_%7BK%7D%7D%7BX%7D_%7Bi%7D%28x%29dx%5E%7Bi%7D%5Cbigg%29%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)

![W[K] =\vec{\mathcal{P}} exp \bigg({\displaystyle \oint_{K}} X_{i}(x)dx^{i}\bigg)](https://s0.wp.com/latex.php?latex=%C2%A0+W%5BK%5D+%3D%5Cvec%7B%5Cmathcal%7BP%7D%7D+%C2%A0exp+%5Cbigg%28%7B%5Cdisplaystyle+%5Coint_%7BK%7D%7D+X_%7Bi%7D%28x%29dx%5E%7Bi%7D%5Cbigg%29+%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)

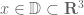 . Let
. Let  . The vector field
. The vector field  be a random vector field defied with respect to a probability space
be a random vector field defied with respect to a probability space  such that
such that  map
map  for all
for all  . Then the total field at any
. Then the total field at any 
![\widehat{L}[K]=L[K]+\widehat{\mathcal{L}}[K]= {\displaystyle \int_{K}}X_{i}(x)dx^{i}+{\displaystyle\int_{K}}\widehat{\mathcal{X}}_{i}(x,\omega)dx^{i}](https://s0.wp.com/latex.php?latex=%C2%A0%5Cwidehat%7BL%7D%5BK%5D%3DL%5BK%5D%2B%5Cwidehat%7B%5Cmathcal%7BL%7D%7D%5BK%5D%3D+%7B%5Cdisplaystyle+%5Cint_%7BK%7D%7DX_%7Bi%7D%28x%29dx%5E%7Bi%7D%2B%7B%5Cdisplaystyle%5Cint_%7BK%7D%7D%5Cwidehat%7B%5Cmathcal%7BX%7D%7D_%7Bi%7D%28x%2C%5Comega%29dx%5E%7Bi%7D+&bg=ffffff&fg=545454&s=0&c=20201002)
![\widehat{W}[K]=exp\bigg({\displaystyle \int_{K}}X_{i}(x)dx^{i}+{\displaystyle \int_{K}}\widehat{\mathcal{X}}_{i}(x,\omega)dx^{i}\bigg)](https://s0.wp.com/latex.php?latex=%C2%A0+%5Cwidehat%7BW%7D%5BK%5D%3Dexp%5Cbigg%28%7B%5Cdisplaystyle+%5Cint_%7BK%7D%7DX_%7Bi%7D%28x%29dx%5E%7Bi%7D%2B%7B%5Cdisplaystyle+%5Cint_%7BK%7D%7D%5Cwidehat%7B%5Cmathcal%7BX%7D%7D_%7Bi%7D%28x%2C%5Comega%29dx%5E%7Bi%7D%5Cbigg%29&bg=ffffff&fg=545454&s=0&c=20201002)

![\mathfrak{W}[K]=\mathbf{E}(\widehat{W}[K])=exp \bigg({\displaystyle \int_{K}}X_{i}(x)dx^{i}+{\displaystyle \int_{K}} \widehat{\mathcal{X}}_{i}(x, \omega)dx^{i} \bigg)](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathfrak%7BW%7D%5BK%5D%3D%5Cmathbf%7BE%7D%28%5Cwidehat%7BW%7D%5BK%5D%29%3Dexp+%5Cbigg%28%7B%5Cdisplaystyle+%5Cint_%7BK%7D%7DX_%7Bi%7D%28x%29dx%5E%7Bi%7D%2B%7B%5Cdisplaystyle+%5Cint_%7BK%7D%7D%C2%A0%5Cwidehat%7B%5Cmathcal%7BX%7D%7D_%7Bi%7D%28x%2C+%5Comega%29dx%5E%7Bi%7D+%5Cbigg%29+&bg=ffffff&fg=545454&s=0&c=20201002)

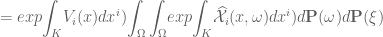

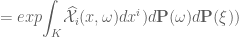
 for
for  so that
so that  . Hence $latex W[K]=W=const.$
. Hence $latex W[K]=W=const.$![\mathbf{\mathfrak{W}}[K]=\mathbf{E}(\widehat{\mathfrak{W}}[K])={\displaystyle \int_{\Omega}} exp{\displaystyle \int_{K}} \widehat{\mathcal{X}}_{i}(x,\omega)dx^{i}d\mathbf{P}(\omega)](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7B%5Cmathfrak%7BW%7D%7D%5BK%5D%3D%5Cmathbf%7BE%7D%28%5Cwidehat%7B%5Cmathfrak%7BW%7D%7D%5BK%5D%29%3D%7B%5Cdisplaystyle+%5Cint_%7B%5COmega%7D%7D+exp%7B%5Cdisplaystyle+%5Cint_%7BK%7D%7D%C2%A0%5Cwidehat%7B%5Cmathcal%7BX%7D%7D_%7Bi%7D%28x%2C%5Comega%29dx%5E%7Bi%7Dd%5Cmathbf%7BP%7D%28%5Comega%29%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{\mathfrak{W}}[K]=\mathbf{E}(\widehat{\mathfrak{W}}[K])={\displaystyle \int_{\Omega}} exp{\displaystyle \oint_{K}} \widehat{\mathcal{X}}_{i}(x,\omega)dx^{i}d\mathbf{P}(\omega)](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7B%5Cmathfrak%7BW%7D%7D%5BK%5D%3D%5Cmathbf%7BE%7D%28%5Cwidehat%7B%5Cmathfrak%7BW%7D%7D%5BK%5D%29%3D%7B%5Cdisplaystyle+%5Cint_%7B%5COmega%7D%7D+exp%7B%5Cdisplaystyle+%5Coint_%7BK%7D%7D+%5Cwidehat%7B%5Cmathcal%7BX%7D%7D_%7Bi%7D%28x%2C%5Comega%29dx%5E%7Bi%7Dd%5Cmathbf%7BP%7D%28%5Comega%29+&bg=ffffff&fg=545454&s=0&c=20201002)
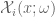 is Gaussian.Such expansions have also been considered in (-
is Gaussian.Such expansions have also been considered in (- . Let
. Let  and
and  . A regulated knot energy functional
. A regulated knot energy functional  is defined as
is defined as




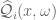 be a random Gaussian vector field defined for all
be a random Gaussian vector field defined for all  and with respect to a triplet
and with respect to a triplet  . Then if:
. Then if: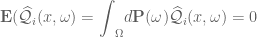
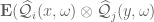

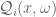 gives
gives![\mathbf{E}(\widehat{W}[K])={\displaystyle \int_{\Omega}}d\mathbf{P}(\omega)exp\bigg({\displaystyle\int_{K}} \widehat{\mathcal{Q}}_{i}(x,\omega)dx^{i}\bigg)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7D%28%5Cwidehat%7BW%7D%5BK%5D%29%3D%7B%5Cdisplaystyle+%5Cint_%7B%5COmega%7D%7Dd%5Cmathbf%7BP%7D%28%5Comega%29exp%5Cbigg%28%7B%5Cdisplaystyle%5Cint_%7BK%7D%7D++%5Cwidehat%7B%5Cmathcal%7BQ%7D%7D_%7Bi%7D%28x%2C%5Comega%29dx%5E%7Bi%7D%5Cbigg%29+&bg=ffffff&fg=545454&s=0&c=20201002) =
= 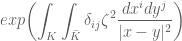
![\mathbf{E}(\widehat{W}[K])={\displaystyle \int_{\Omega}}d\mathbf{P}(\omega)exp \bigg(i{\displaystyle\int_{K}} \widehat{\mathcal{Q}}_{i}(x,\omega)dx^{i}\bigg)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7D%28%5Cwidehat%7BW%7D%5BK%5D%29%3D%7B%5Cdisplaystyle+%5Cint_%7B%5COmega%7D%7Dd%5Cmathbf%7BP%7D%28%5Comega%29exp+%C2%A0%5Cbigg%28i%7B%5Cdisplaystyle%5Cint_%7BK%7D%7D++%5Cwidehat%7B%5Cmathcal%7BQ%7D%7D_%7Bi%7D%28x%2C%5Comega%29dx%5E%7Bi%7D%5Cbigg%29+&bg=ffffff&fg=545454&s=0&c=20201002) =
= 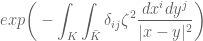

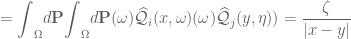
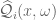 gives
gives![\mathbf{E}(\widehat{W}[K])={\displaystyle \int_{\Omega}}d\mathbf{P}(\omega)exp\bigg({\displaystyle\int_{K}}\widehat{\mathcal{Q}}_{i}(x,\omega)dx^{i}\bigg)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7D%28%5Cwidehat%7BW%7D%5BK%5D%29%3D%7B%5Cdisplaystyle+%5Cint_%7B%5COmega%7D%7Dd%5Cmathbf%7BP%7D%28%5Comega%29exp%5Cbigg%28%7B%5Cdisplaystyle%5Cint_%7BK%7D%7D%5Cwidehat%7B%5Cmathcal%7BQ%7D%7D_%7Bi%7D%28x%2C%5Comega%29dx%5E%7Bi%7D%5Cbigg%29+&bg=ffffff&fg=545454&s=0&c=20201002) =
= 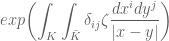
![\mathbf{E}(\widehat{W}[K])={\displaystyle \int_{\Omega}}d\mathbf{P}(\omega)exp\bigg(i{\displaystyle\int_{K}}\widehat{\mathcal{Q}}_{i}(x,\omega)dx^{i}\bigg)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7D%28%5Cwidehat%7BW%7D%5BK%5D%29%3D%7B%5Cdisplaystyle+%5Cint_%7B%5COmega%7D%7Dd%5Cmathbf%7BP%7D%28%5Comega%29exp%5Cbigg%28i%7B%5Cdisplaystyle%5Cint_%7BK%7D%7D%5Cwidehat%7B%5Cmathcal%7BQ%7D%7D_%7Bi%7D%28x%2C%5Comega%29dx%5E%7Bi%7D%5Cbigg%29+&bg=ffffff&fg=545454&s=0&c=20201002) =
= 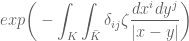
 be a RVF on a domain
be a RVF on a domain  and for all
and for all  , let
, let 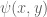 be a deterministic continuous and bounded function such that
be a deterministic continuous and bounded function such that 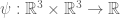 . The function can also be complex such that
. The function can also be complex such that  . The stochastic volume integral is the mean-square Riemann integral
. The stochastic volume integral is the mean-square Riemann integral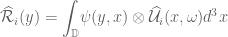
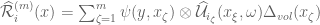
 is a volume element centered on
is a volume element centered on 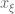 and
and  . The integral then exists if
. The integral then exists if 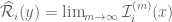
 then
then  . When
. When 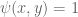 then
then
 =
= <
< 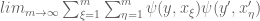
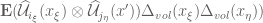
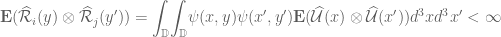
 and
and 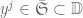 . Let
. Let 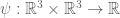 .
.
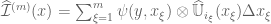 ,
, is a line element centered on
is a line element centered on  is the length of the line. The stochastic line integral then exists if
is the length of the line. The stochastic line integral then exists if . If
. If 

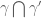 of two curves or knots is described by the correlations
of two curves or knots is described by the correlations


 =
= 

 of (-), then setting
of (-), then setting 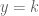 with
with 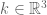 and
and ![f(x,k)=\frac{1}{2\pi}^{3/2}\exp[-ik_{i}x^{i}]](https://s0.wp.com/latex.php?latex=%C2%A0f%28x%2Ck%29%3D%5Cfrac%7B1%7D%7B2%5Cpi%7D%5E%7B3%2F2%7D%5Cexp%5B-ik_%7Bi%7Dx%5E%7Bi%7D%5D&bg=ffffff&fg=545454&s=0&c=20201002) gives a stochastic Fourier integral.
gives a stochastic Fourier integral.![\widehat{\mathcal{U}}_{i}(k)=\frac{1}{2\pi^{3/2}}\int d^{3}k\widehat{\mathcal{U}}_{i}(x)\exp[ik_{i}x^{i}]](https://s0.wp.com/latex.php?latex=%5Cwidehat%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28k%29%3D%5Cfrac%7B1%7D%7B2%5Cpi%5E%7B3%2F2%7D%7D%5Cint+d%5E%7B3%7Dk%5Cwidehat%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28x%29%5Cexp%5Bik_%7Bi%7Dx%5E%7Bi%7D%5D%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
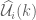 then the random vector field
then the random vector field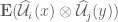
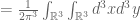
![exp[-i (x_{i} k^{i})]](https://s0.wp.com/latex.php?latex=%C2%A0exp%5B-i+%28x_%7Bi%7D+k%5E%7Bi%7D%29%5D+%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
![exp[-ik_{j}y^{j}] \mathcal{C}ov_{ij}(x,y)<\infty](https://s0.wp.com/latex.php?latex=exp%5B-ik_%7Bj%7Dy%5E%7Bj%7D%5D+%5Cmathcal%7BC%7Dov_%7Bij%7D%28x%2Cy%29%3C%5Cinfty+&bg=ffffff&fg=545454&s=0&c=20201002)
 for a Gaussian RVF. Equation (-) defines the cross spectral density function, provided the integral exists.
for a Gaussian RVF. Equation (-) defines the cross spectral density function, provided the integral exists.![\widetilde{\mathcal{U}}_{i}(x)=(2\pi)^{-3/2}\int_{\mathbb{R}^{3}}d^{3}x \widetilde{\mathcal{U}}_{i}({x}) exp[-i k x ]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28x%29%3D%282%5Cpi%29%5E%7B-3%2F2%7D%5Cint_%7B%5Cmathbb%7BR%7D%5E%7B3%7D%7Dd%5E%7B3%7Dx+%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28%7Bx%7D%29+exp%5B-i+k+%C2%A0x+%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
![\widetilde{\mathcal{U}}_{i}(k)= (2\pi)^{-3} \int_{\mathbb{R}^{3}} d^{3}k \widetilde{\mathcal{U}}_{i}({k}) exp[+i k x]](https://s0.wp.com/latex.php?latex=%C2%A0+%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28k%29%3D+%282%5Cpi%29%5E%7B-3%7D+%5Cint_%7B%5Cmathbb%7BR%7D%5E%7B3%7D%7D+d%5E%7B3%7Dk+%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28%7Bk%7D%29+exp%5B%2Bi+k+x%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
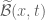 extends over all space and does not decay to zero as
extends over all space and does not decay to zero as 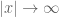 , as is required for the existence of a classical Fourier transform. The resolution of this difficulty is essentially to define the transform of
, as is required for the existence of a classical Fourier transform. The resolution of this difficulty is essentially to define the transform of  over a finite volume or domain
over a finite volume or domain  and consider the limit as the volume grows large and approaches infinity.
and consider the limit as the volume grows large and approaches infinity.![\widetilde{\mathcal{U}}_{i}^{[l]}({k})](https://s0.wp.com/latex.php?latex=%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%5E%7B%5Bl%5D%7D%28%7Bk%7D%29&bg=ffffff&fg=545454&s=0&c=20201002) and its
and its![\widehat{\mathcal{U}}_{i}^{[l]*}({k})](https://s0.wp.com/latex.php?latex=%5Cwidehat%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%5E%7B%5Bl%5D%2A%7D%28%7Bk%7D%29&bg=ffffff&fg=545454&s=0&c=20201002) can be defined as
can be defined as![\widehat{\mathcal{U}}_{i}^{[l]}({k}) = (2\pi)^{-3}\int _{\mathbb{D}_{l}}d^{3}x~\widetilde{\mathcal{U}}_{i}({x},t) exp[-i k x]](https://s0.wp.com/latex.php?latex=%C2%A0+%5Cwidehat%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%5E%7B%5Bl%5D%7D%28%7Bk%7D%29+%3D+%282%5Cpi%29%5E%7B-3%7D%5Cint+_%7B%5Cmathbb%7BD%7D_%7Bl%7D%7Dd%5E%7B3%7Dx%7E%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28%7Bx%7D%2Ct%29+exp%5B-i+k+x%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
![\widehat{\mathcal{U}}_{i}^{[l]*}({k})= (2\pi)^{-3}\int _{\mathfrak{D}_{l}} d^{3}y \widehat{\mathcal{U}}_{i}({y})exp[+i{k}.{y}]](https://s0.wp.com/latex.php?latex=%5Cwidehat%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%5E%7B%5Bl%5D%2A%7D%28%7Bk%7D%29%3D+%282%5Cpi%29%5E%7B-3%7D%5Cint+_%7B%5Cmathfrak%7BD%7D_%7Bl%7D%7D+d%5E%7B3%7Dy+%5Cwidehat%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28%7By%7D%29exp%5B%2Bi%7Bk%7D.%7By%7D%5D%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
 and where
and where  is a cubic volume defined by
is a cubic volume defined by ![x_{1}\in [-l,l]](https://s0.wp.com/latex.php?latex=%C2%A0x_%7B1%7D%5Cin+%5B-l%2Cl%5D&bg=ffffff&fg=545454&s=0&c=20201002) ,
, ![x_{2}\in [-l,l]](https://s0.wp.com/latex.php?latex=x_%7B2%7D%5Cin+%5B-l%2Cl%5D&bg=ffffff&fg=545454&s=0&c=20201002) ,
, ![x_{3}\in [-l,l]](https://s0.wp.com/latex.php?latex=x_%7B3%7D%5Cin+%5B-l%2Cl%5D&bg=ffffff&fg=545454&s=0&c=20201002) and
and  defines the sides of the cube. Taking the product of the transform and its conjugate then averaging gives the spectral moment
defines the sides of the cube. Taking the product of the transform and its conjugate then averaging gives the spectral moment![\mathbf{E}(\widehat{\mathcal{U}}^{[l]}({k})\circ\widehat{\mathcal{U}}^{l*}({k})) =(2\pi)^{-6}\int_{\mathfrak{D}_{l}}d^{3}x\int_{\mathbb{D}_{l}}d^{3}y G_{ij}({x}-{y},t)\exp[-i{k}.({x}-{y})]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BE%7D%28%5Cwidehat%7B%5Cmathcal%7BU%7D%7D%5E%7B%5Bl%5D%7D%28%7Bk%7D%29%5Ccirc%5Cwidehat%7B%5Cmathcal%7BU%7D%7D%5E%7Bl%2A%7D%28%7Bk%7D%29%29+%3D%282%5Cpi%29%5E%7B-6%7D%5Cint_%7B%5Cmathfrak%7BD%7D_%7Bl%7D%7Dd%5E%7B3%7Dx%5Cint_%7B%5Cmathbb%7BD%7D_%7Bl%7D%7Dd%5E%7B3%7Dy+G_%7Bij%7D%28%7Bx%7D-%7By%7D%2Ct%29%5Cexp%5B-i%7Bk%7D.%28%7Bx%7D-%7By%7D%29%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
 or
or 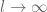 . The correlation
. The correlation  is a function of
is a function of  owing to its homogeneity, and there is a decorrelation for
owing to its homogeneity, and there is a decorrelation for  . The length scale over which
. The length scale over which  has significant non-zero values is
has significant non-zero values is  with
with  being the correlation length. Let
being the correlation length. Let  be a vector separation of two points. Replacing
be a vector separation of two points. Replacing  as an integration variable in (36) gives
as an integration variable in (36) gives![\mathbf{E}(\widetilde{\mathcal{U}}_{i}^{[l]}({k})\otimes\widetilde{\mathcal{U}}_{j}^{[l*]}({k}))=(2\pi)^{-6} \int_{\mathbb{D}_{l}} d^{3}x \int_{\mathbb{D}_{l}'} d^{3}r G_{ij}({r},t) exp[-i{k}.{r}]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BE%7D%28%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%5E%7B%5Bl%5D%7D%28%7Bk%7D%29%5Cotimes%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bj%7D%5E%7B%5Bl%2A%5D%7D%28%7Bk%7D%29%29%3D%282%5Cpi%29%5E%7B-6%7D+%5Cint_%7B%5Cmathbb%7BD%7D_%7Bl%7D%7D+d%5E%7B3%7Dx+%5Cint_%7B%5Cmathbb%7BD%7D_%7Bl%7D%27%7D+d%5E%7B3%7Dr+G_%7Bij%7D%28%7Br%7D%2Ct%29+exp%5B-i%7Bk%7D.%7Br%7D%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
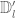 depends on on
depends on on  and is defined by
and is defined by ![r_{1}\in [x_{1}-l,x_{2}+l]](https://s0.wp.com/latex.php?latex=r_%7B1%7D%5Cin+%5Bx_%7B1%7D-l%2Cx_%7B2%7D%2Bl%5D&bg=ffffff&fg=545454&s=0&c=20201002) ,
, ![r_{2}\in [x_{2}-l,x_{2}+l]](https://s0.wp.com/latex.php?latex=r_%7B2%7D%5Cin+%5Bx_%7B2%7D-l%2Cx_%7B2%7D%2Bl%5D&bg=ffffff&fg=545454&s=0&c=20201002) ,
, ![r_{3}\in[x_{3}-l,x_{3}+l]](https://s0.wp.com/latex.php?latex=r_%7B3%7D%5Cin%5Bx_%7B3%7D-l%2Cx_%7B3%7D%2Bl%5D&bg=ffffff&fg=545454&s=0&c=20201002) . The cube
. The cube  has sides
has sides 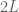 and is centred on
and is centred on  . The integral is only significantly different from zero when $| r |=O(l)$ and this region lies well within
. The integral is only significantly different from zero when $| r |=O(l)$ and this region lies well within 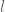 is many correlation lengths from the boundary of
is many correlation lengths from the boundary of 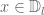 , the integration over
, the integration over  can be carried to infinity.
can be carried to infinity.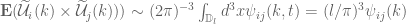
 applies everywhere except when
applies everywhere except when  . The spectral correlation is where the integration variable has been changed from
. The spectral correlation is where the integration variable has been changed from  . Again. provided that
. Again. provided that 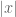 is many correlation lengths from the boundary of
is many correlation lengths from the boundary of ![\mathbf{E}((\widetilde{\mathcal{U}}_{i}^{[l]}({k},t)\circ\widetilde{\mathcal{U}}_{j}^{[l*]}(k)]] )\sim\psi_{ij}(k',t)\Xi_{\ell}(k-k')](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BE%7D%28%28%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%5E%7B%5Bl%5D%7D%28%7Bk%7D%2Ct%29%5Ccirc%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bj%7D%5E%7B%5Bl%2A%5D%7D%28k%29%5D%5D+%29%5Csim%5Cpsi_%7Bij%7D%28k%27%2Ct%29%5CXi_%7B%5Cell%7D%28k-k%27%29+&bg=ffffff&fg=545454&s=0&c=20201002)
![\Xi_{l}(k-k')= \frac{sin[(k_{1}-k_{1}')l]sin[(k_{2}-k_{2}')l]sin[(k_{3}-k_{3}')l]}{\pi^{3} (k_{1}-k_{1}')(k_{2}-k_{2}')(k_{3}-k_{3}')}](https://s0.wp.com/latex.php?latex=%5CXi_%7Bl%7D%28k-k%27%29%3D+%5Cfrac%7Bsin%5B%28k_%7B1%7D-k_%7B1%7D%27%29l%5Dsin%5B%28k_%7B2%7D-k_%7B2%7D%27%29l%5Dsin%5B%28k_%7B3%7D-k_%7B3%7D%27%29l%5D%7D%7B%5Cpi%5E%7B3%7D%C2%A0%28k_%7B1%7D-k_%7B1%7D%27%29%28k_%7B2%7D-k_%7B2%7D%27%29%28k_%7B3%7D-k_%7B3%7D%27%29%7D+&bg=ffffff&fg=545454&s=0&c=20201002)
 has a maximum peak at
has a maximum peak at 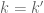 and becomes increasingly sharply peaked about
and becomes increasingly sharply peaked about  as
as 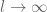 with the integral
with the integral 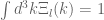 always satisfied. It follows that
always satisfied. It follows that 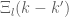 has all the properties of a delta function so that
has all the properties of a delta function so that 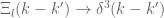 as
as  . This then leads
. This then leads
 with
with  since the delta function is effectively zero when
since the delta function is effectively zero when 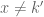 . Since
. Since  is real the complex conjugate of (-) gives
is real the complex conjugate of (-) gives  so that the spectral correlation (in the infinite
so that the spectral correlation (in the infinite 
 The essential idea is to decompose the turbulent fluctuations about the mean flow into sinusoidal components and study the distribution of turbulent energy amongst the different wave vectors representing the different scales of turbulence.
The essential idea is to decompose the turbulent fluctuations about the mean flow into sinusoidal components and study the distribution of turbulent energy amongst the different wave vectors representing the different scales of turbulence.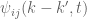 is given by the Fourier transform
is given by the Fourier transform of the stress tensor
of the stress tensor  .
.![\psi_{ij}(k,t)=(2\pi)^{-3}\int_{\mathbb{R}^{3}}d^{3}x S_{ij}(x,y,t)\exp[-k.y-x]=(2\pi)^{-3}](https://s0.wp.com/latex.php?latex=%C2%A0%5Cpsi_%7Bij%7D%28k%2Ct%29%3D%282%5Cpi%29%5E%7B-3%7D%5Cint_%7B%5Cmathbb%7BR%7D%5E%7B3%7D%7Dd%5E%7B3%7Dx+S_%7Bij%7D%28x%2Cy%2Ct%29%5Cexp%5B-k.y-x%5D%3D%282%5Cpi%29%5E%7B-3%7D&bg=ffffff&fg=545454&s=0&c=20201002) *
*![\int d^{3}x\mathbf{E}(\arrowvert\widetilde{\mathcal{U}}_{i}(x,t)\circ\widetilde{\mathcal{U}}_{j}(y,t)\arrowvert exp[-ik.r]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cint+d%5E%7B3%7Dx%5Cmathbf%7BE%7D%28%5Carrowvert%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28x%2Ct%29%5Ccirc%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bj%7D%28y%2Ct%29%5Carrowvert+exp%5B-ik.r%5D&bg=ffffff&fg=545454&s=0&c=20201002)
 as the turbulence evolves. The inverse transform is
as the turbulence evolves. The inverse transform is  , which is an integral over all 3-dimensional wavenumber space. Setting
, which is an integral over all 3-dimensional wavenumber space. Setting 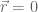 and i=j in (-) gives the stress tensor of (-)
and i=j in (-) gives the stress tensor of (-)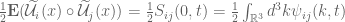
 can be interpreted as the distribution of turbulent energy over the various wavenumbers. The stresses and spectral functions have the symmetries
can be interpreted as the distribution of turbulent energy over the various wavenumbers. The stresses and spectral functions have the symmetries  and
and 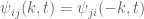 . Also
. Also  leading to
leading to 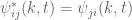 , which implies that
, which implies that  has dimensions of inverse length. One can interpret the length scale
has dimensions of inverse length. One can interpret the length scale  as the spatial scale represented by wavenumber
as the spatial scale represented by wavenumber  . For example if
. For example if  represent the scales of turbulence that contain most of the kinetic energy. The spectral function then has its maximum values for
represent the scales of turbulence that contain most of the kinetic energy. The spectral function then has its maximum values for  and decays to zero as
and decays to zero as 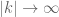 . The stress tensor can then be represented as the inverse Fourier transform
. The stress tensor can then be represented as the inverse Fourier transform
![=\int_{\mathbb{R}^{3}} d^{3}k\int_{\mathbb{R}^{3}} d^{3}k' \psi_{ij}(k)\delta^{3}(k-\beta')\exp[i k'.(x-y)]](https://s0.wp.com/latex.php?latex=%3D%5Cint_%7B%5Cmathbb%7BR%7D%5E%7B3%7D%7D+d%5E%7B3%7Dk%5Cint_%7B%5Cmathbb%7BR%7D%5E%7B3%7D%7D+d%5E%7B3%7Dk%27+%5Cpsi_%7Bij%7D%28k%29%5Cdelta%5E%7B3%7D%28k-%5Cbeta%27%29%5Cexp%5Bi+k%27.%28x-y%29%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
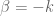 and the integration range is taken over all
and the integration range is taken over all 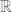 space since we take the spectral function to be such that the Fourier integrals now converge. Equation (44) becomes
space since we take the spectral function to be such that the Fourier integrals now converge. Equation (44) becomes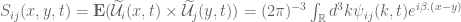
![exp[i{\beta}.(x-y)]=exp[-ik.(x-y)]=\exp[ik.(y-x)]](https://s0.wp.com/latex.php?latex=exp%5Bi%7B%5Cbeta%7D.%28x-y%29%5D%3Dexp%5B-ik.%28x-y%29%5D%3D%5Cexp%5Bik.%28y-x%29%5D&bg=ffffff&fg=545454&s=0&c=20201002) so that
so that![S_{ij}(x,y,t)=\mathbf{E})\lbrace\widetilde{\mathcal{U}}_{i}(x,t) \otimes\widetilde{\mathcal{U}}_{j}({y},t) \rbrace=(2\pi)^{-3}\int_{\mathbb{R}^{3}} d^{3}k~\psi_{ij}(k,t)exp[i {k}.(y-x)]](https://s0.wp.com/latex.php?latex=%C2%A0S_%7Bij%7D%28x%2Cy%2Ct%29%3D%5Cmathbf%7BE%7D%29%5Clbrace%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28x%2Ct%29+%5Cotimes%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bj%7D%28%7By%7D%2Ct%29+%5Crbrace%3D%282%5Cpi%29%5E%7B-3%7D%5Cint_%7B%5Cmathbb%7BR%7D%5E%7B3%7D%7D+d%5E%7B3%7Dk%7E%5Cpsi_%7Bij%7D%28k%2Ct%29exp%5Bi+%7Bk%7D.%28y-x%29%5D%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
![\frac{d}{d\xi_{j}}\mathbf{E}(\widetilde{\mathcal{U}}_{i}(x,t)\otimes\widetilde{\mathcal{U}}_{j}({x}+{\xi},t)) = (2\pi)^{-3}\int_{\mathbb{R}^{3}} d^{3}k ~ik_{j}\psi_{ij}(k,t)exp[ik_{j}\xi_{j}]=0](https://s0.wp.com/latex.php?latex=%C2%A0%5Cfrac%7Bd%7D%7Bd%5Cxi_%7Bj%7D%7D%5Cmathbf%7BE%7D%28%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28x%2Ct%29%5Cotimes%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bj%7D%28%7Bx%7D%2B%7B%5Cxi%7D%2Ct%29%29+%3D+%282%5Cpi%29%5E%7B-3%7D%5Cint_%7B%5Cmathbb%7BR%7D%5E%7B3%7D%7D+d%5E%7B3%7Dk+%7Eik_%7Bj%7D%5Cpsi_%7Bij%7D%28k%2Ct%29exp%5Bik_%7Bj%7D%5Cxi_%7Bj%7D%5D%3D0%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
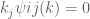 . The most general form is then
. The most general form is then
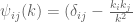 be the spectral function corresponding to the 2-point function
be the spectral function corresponding to the 2-point function![\mathbf{E}(\widetilde{\mathcal{U}}_{i}(x,t)\times\widetilde{\mathcal{U}}_{j}(y,t))= \frac{1}{(2\pi)^{3/2}}\int_{\mathbb{R}^{3}}d^{3}k \psi_{ij}(k)\exp[ik^{i}(x-y)_{i}]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7D%28%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28x%2Ct%29%5Ctimes%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bj%7D%28y%2Ct%29%29%3D+%5Cfrac%7B1%7D%7B%282%5Cpi%29%5E%7B3%2F2%7D%7D%5Cint_%7B%5Cmathbb%7BR%7D%5E%7B3%7D%7Dd%5E%7B3%7Dk+%5Cpsi_%7Bij%7D%28k%29%5Cexp%5Bik%5E%7Bi%7D%28x-y%29_%7Bi%7D%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
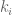 then determines the form of the correlation for the GRVFS
then determines the form of the correlation for the GRVFS 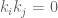 then
then  and
and![\mathbf{E}(\widetilde{\mathcal{U}}_{i}(x)\times\widetilde{\mathcal{U}}_{j}(y))=\frac{1}{(2\pi)^{3/2}}\int_{\mathbb{R}^{3}}d^{3}k \delta_{ij}(k)\exp[ik^{i}(x-y)_{i}]=\delta_{ij}\delta^{(3)}(x-y)](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BE%7D%28%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28x%29%5Ctimes%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bj%7D%28y%29%29%3D%5Cfrac%7B1%7D%7B%282%5Cpi%29%5E%7B3%2F2%7D%7D%5Cint_%7B%5Cmathbb%7BR%7D%5E%7B3%7D%7Dd%5E%7B3%7Dk+%5Cdelta_%7Bij%7D%28k%29%5Cexp%5Bik%5E%7Bi%7D%28x-y%29_%7Bi%7D%5D%3D%5Cdelta_%7Bij%7D%5Cdelta%5E%7B%283%29%7D%28x-y%29%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
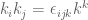 and
and  then
then![\mathbf{E}(\widetilde{\mathcal{U}}_{i}({x})\circ\widetilde{\mathcal{U}}_{j}(y))= \frac{1}{(2\pi)^{3/2}}\int_{\mathbb{R}^{3}}d^{3}k \epsilon_{ijk}\frac{k^{k}}{k^{2}} exp[ik^{i}(x-y)_{i}]=\frac{1}{4\pi}\epsilon_{ijk}|x-y|^{k}\|x-y\|^{-3}](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BE%7D%28%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28%7Bx%7D%29%5Ccirc%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bj%7D%28y%29%29%3D%C2%A0%5Cfrac%7B1%7D%7B%282%5Cpi%29%5E%7B3%2F2%7D%7D%5Cint_%7B%5Cmathbb%7BR%7D%5E%7B3%7D%7Dd%5E%7B3%7Dk+%5Cepsilon_%7Bijk%7D%5Cfrac%7Bk%5E%7Bk%7D%7D%7Bk%5E%7B2%7D%7D%C2%A0exp%5Bik%5E%7Bi%7D%28x-y%29_%7Bi%7D%5D%3D%5Cfrac%7B1%7D%7B4%5Cpi%7D%5Cepsilon_%7Bijk%7D%7Cx-y%7C%5E%7Bk%7D%5C%7Cx-y%5C%7C%5E%7B-3%7D+&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{E}[\widehat{\mathcal{F}}_{i}(x)]=0](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7D%5B%5Cwidehat%7B%5Cmathcal%7BF%7D%7D_%7Bi%7D%28x%29%5D%3D0&bg=ffffff&fg=545454&s=0&c=20201002) . Let
. Let ![\mathbf{E}[\widehat{\mathcal{F}}_{i}(x)\times\widehat{\mathcal{F}}_{i}(x)]= \delta_{ij}\delta^{3}(x-y)](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BE%7D%5B%5Cwidehat%7B%5Cmathcal%7BF%7D%7D_%7Bi%7D%28x%29%5Ctimes%5Cwidehat%7B%5Cmathcal%7BF%7D%7D_%7Bi%7D%28x%29%5D%3D+%5Cdelta_%7Bij%7D%5Cdelta%5E%7B3%7D%28x-y%29+&bg=ffffff&fg=545454&s=0&c=20201002)
 for all
for all ![\mathbf{E}[\widehat{\mathcal{B}}_{i}(x)\times\widehat{\mathcal{B}}_{i}(y)]= \delta_{ij}|x-y|^{-1}](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BE%7D%5B%5Cwidehat%7B%5Cmathcal%7BB%7D%7D_%7Bi%7D%28x%29%5Ctimes%5Cwidehat%7B%5Cmathcal%7BB%7D%7D_%7Bi%7D%28y%29%5D%3D+%5Cdelta_%7Bij%7D%7Cx-y%7C%5E%7B-1%7D+&bg=ffffff&fg=545454&s=0&c=20201002)
 for all
for all ![\mathbf{E}[\widehat{\mathcal{G}}_{i}(x)\times\widehat{\mathcal{G}}_{i}(y)]= \frac{1}{4\pi}\epsilon_{ijk}(x-y)^{k}|x-y|^{-3}](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BE%7D%5B%5Cwidehat%7B%5Cmathcal%7BG%7D%7D_%7Bi%7D%28x%29%5Ctimes%5Cwidehat%7B%5Cmathcal%7BG%7D%7D_%7Bi%7D%28y%29%5D%3D%C2%A0%5Cfrac%7B1%7D%7B4%5Cpi%7D%5Cepsilon_%7Bijk%7D%28x-y%29%5E%7Bk%7D%7Cx-y%7C%5E%7B-3%7D&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{E}[\widehat{\mathcal{R}}_{i}(x)\otimes\widehat{\mathcal{R}}_{j}(y)]=K_{ij}(x-y)](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BE%7D%5B%5Cwidehat%7B%5Cmathcal%7BR%7D%7D_%7Bi%7D%28x%29%5Cotimes%5Cwidehat%7B%5Cmathcal%7BR%7D%7D_%7Bj%7D%28y%29%5D%3DK_%7Bij%7D%28x-y%29&bg=ffffff&fg=545454&s=0&c=20201002) then
then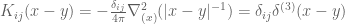


![\mathbf{E}[\widehat{\mathcal{B}}_{i}(x)\otimes\widehat{\mathcal{B}}_{j}(x)]\equiv G_{ij}(x-y)=\delta_{ij}|x-y|^{-1}](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7D%5B%5Cwidehat%7B%5Cmathcal%7BB%7D%7D_%7Bi%7D%28x%29%5Cotimes%5Cwidehat%7B%5Cmathcal%7BB%7D%7D_%7Bj%7D%28x%29%5D%5Cequiv+G_%7Bij%7D%28x-y%29%3D%5Cdelta_%7Bij%7D%7Cx-y%7C%5E%7B-1%7D+&bg=ffffff&fg=545454&s=0&c=20201002)
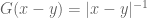 . Next, given
. Next, given 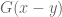 there is a Greens function
there is a Greens function 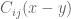 such that
such that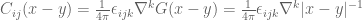
![C(x-y)=\mathbf{E}[\widehat{\mathcal{G}}_{i}(x)\otimes\widehat{\mathcal{G}}_{j}(x)] =\frac{1}{4\pi}\epsilon_{ijk}(x-y)^{k}|x-y|^{-3}](https://s0.wp.com/latex.php?latex=%C2%A0C%28x-y%29%3D%5Cmathbf%7BE%7D%5B%5Cwidehat%7B%5Cmathcal%7BG%7D%7D_%7Bi%7D%28x%29%5Cotimes%5Cwidehat%7B%5Cmathcal%7BG%7D%7D_%7Bj%7D%28x%29%5D+%3D%5Cfrac%7B1%7D%7B4%5Cpi%7D%5Cepsilon_%7Bijk%7D%28x-y%29%5E%7Bk%7D%7Cx-y%7C%5E%7B-3%7D&bg=ffffff&fg=545454&s=0&c=20201002)
 and
and ![\mathbf{E}(\widetilde{\mathcal{U}}_{i}({x})\times\widetilde{\mathcal{U}}_{j}({y})) =\frac{1}{(2\pi)^{3/2}}\int_{\mathbb{R}^{3}}d^{3}k \delta_{ij}(k)\exp[ik^{i}(x-y)_{i}]=\delta_{ij}\delta^{(3)}(x-y)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BE%7D%28%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28%7Bx%7D%29%5Ctimes%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bj%7D%28%7By%7D%29%29+%3D%5Cfrac%7B1%7D%7B%282%5Cpi%29%5E%7B3%2F2%7D%7D%5Cint_%7B%5Cmathbb%7BR%7D%5E%7B3%7D%7Dd%5E%7B3%7Dk+%5Cdelta_%7Bij%7D%28k%29%5Cexp%5Bik%5E%7Bi%7D%28x-y%29_%7Bi%7D%5D%3D%5Cdelta_%7Bij%7D%5Cdelta%5E%7B%283%29%7D%28x-y%29%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
 be a ball of radius
be a ball of radius  and
and  . If
. If  the delta-function is ‘smeared-out’ over
the delta-function is ‘smeared-out’ over  into a very narrow and highly peaked rectangular or top-hat function of width
into a very narrow and highly peaked rectangular or top-hat function of width ![\delta_{ij}\delta(x-y)\rightarrow \xi^{-2}\Pi[\xi^{-1}(|x-y|-\tfrac{1}{2}\xi)]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cdelta_%7Bij%7D%5Cdelta%28x-y%29%5Crightarrow+%5Cxi%5E%7B-2%7D%5CPi%5B%5Cxi%5E%7B-1%7D%28%7Cx-y%7C-%5Ctfrac%7B1%7D%7B2%7D%5Cxi%29%5D%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
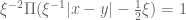 ~for
~for 
 for
for 
![\psi_{ij}(k)=\tfrac{1}{2\pi}^{1/2}\delta_{ij}sinc[k/2] = \tfrac{1}{2\pi}^{1/2}k^{-1}\sin[k/2]](https://s0.wp.com/latex.php?latex=%5Cpsi_%7Bij%7D%28k%29%3D%5Ctfrac%7B1%7D%7B2%5Cpi%7D%5E%7B1%2F2%7D%5Cdelta_%7Bij%7Dsinc%5Bk%2F2%5D+%3D+%5Ctfrac%7B1%7D%7B2%5Cpi%7D%5E%7B1%2F2%7Dk%5E%7B-1%7D%5Csin%5Bk%2F2%5D&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathscr{F}[sinc[k/2]]=\mathbf{E}(\widetilde{\mathcal{U}}_{i}({x})\times\widetilde{\mathcal{U}}_{j}({y}))](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathscr%7BF%7D%5Bsinc%5Bk%2F2%5D%5D%3D%5Cmathbf%7BE%7D%28%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28%7Bx%7D%29%5Ctimes%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bj%7D%28%7By%7D%29%29&bg=ffffff&fg=545454&s=0&c=20201002)
![=\frac{1}{(2\pi)^{3/2}}\int_{\mathbb{R}^{3}}d^{3}k\delta_{ij}~sinc[k/2] \exp[ik^{i}(x-y)_{i}]=\delta_{ij}\Pi[x-y]](https://s0.wp.com/latex.php?latex=%C2%A0%3D%5Cfrac%7B1%7D%7B%282%5Cpi%29%5E%7B3%2F2%7D%7D%5Cint_%7B%5Cmathbb%7BR%7D%5E%7B3%7D%7Dd%5E%7B3%7Dk%5Cdelta_%7Bij%7D%7Esinc%5Bk%2F2%5D+%5Cexp%5Bik%5E%7Bi%7D%28x-y%29_%7Bi%7D%5D%3D%5Cdelta_%7Bij%7D%5CPi%5Bx-y%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
![|x-y|\rightarrow [|x-y|-\tfrac{1}{2}\xi]\xi^{-1}](https://s0.wp.com/latex.php?latex=%7Cx-y%7C%5Crightarrow+%5B%7Cx-y%7C-%5Ctfrac%7B1%7D%7B2%7D%5Cxi%5D%5Cxi%5E%7B-1%7D&bg=ffffff&fg=545454&s=0&c=20201002) .
.![\mathbf{E}(\widetilde{\mathcal{U}}_{i}({x})\times\widetilde{\mathcal{U}}_{j}({y}))= \frac{\alpha}{\xi^{2}}\delta_{ij}\Pi[\xi^{-1}(|x-y|-\tfrac{1}{2}\xi)]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BE%7D%28%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bi%7D%28%7Bx%7D%29%5Ctimes%5Cwidetilde%7B%5Cmathcal%7BU%7D%7D_%7Bj%7D%28%7By%7D%29%29%3D+%5Cfrac%7B%5Calpha%7D%7B%5Cxi%5E%7B2%7D%7D%5Cdelta_%7Bij%7D%5CPi%5B%5Cxi%5E%7B-1%7D%28%7Cx-y%7C-%5Ctfrac%7B1%7D%7B2%7D%5Cxi%29%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{P}[\psi(t)=\infty]=0](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BP%7D%5B%5Cpsi%28t%29%3D%5Cinfty%5D%3D0&bg=ffffff&fg=545454&s=0&c=20201002) for all
for all  where
where
 is the blowup time for the unperturbed system. From the perspective of consistency, the same conclusion should also follow from a Fokker-Planck equation, or Kolmogorov’s second equation, which is essentially an equation for conservation of probability. For a pure diffusion with non drift, the FP equation will reduce to a diffusion equation for the underlying probability density function.
is the blowup time for the unperturbed system. From the perspective of consistency, the same conclusion should also follow from a Fokker-Planck equation, or Kolmogorov’s second equation, which is essentially an equation for conservation of probability. For a pure diffusion with non drift, the FP equation will reduce to a diffusion equation for the underlying probability density function.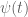 be a generic diffusion satisfying athe nonlinear SDE
be a generic diffusion satisfying athe nonlinear SDE![d\widehat{\psi}(T)=U[\psi(t)]dt +V[\psi(t)]\circ d\widehat{\mathcal{B}}(t)](https://s0.wp.com/latex.php?latex=d%5Cwidehat%7B%5Cpsi%7D%28T%29%3DU%5B%5Cpsi%28t%29%5Ddt+%2BV%5B%5Cpsi%28t%29%5D%5Ccirc+d%5Cwidehat%7B%5Cmathcal%7BB%7D%7D%28t%29%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
 and
and 
 with
with  . A pure drift-free diffusion is then
. A pure drift-free diffusion is then![d\widehat{\psi}(T)=V[\psi(t)]\circ d\widehat{\mathcal{B}}(t)=\lim_{U\rightarrow 0}U[\psi(t)]dt +V[\psi(t)]\circ d\widehat{\mathcal{B}}(t)](https://s0.wp.com/latex.php?latex=%C2%A0d%5Cwidehat%7B%5Cpsi%7D%28T%29%3DV%5B%5Cpsi%28t%29%5D%5Ccirc+d%5Cwidehat%7B%5Cmathcal%7BB%7D%7D%28t%29%3D%5Clim_%7BU%5Crightarrow+0%7DU%5B%5Cpsi%28t%29%5Ddt+%2BV%5B%5Cpsi%28t%29%5D%5Ccirc+d%5Cwidehat%7B%5Cmathcal%7BB%7D%7D%28t%29&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathscr{P}[\psi(T),t]](https://s0.wp.com/latex.php?latex=%C2%A0+%5Cmathscr%7BP%7D%5B%5Cpsi%28T%29%2Ct%5D&bg=ffffff&fg=545454&s=0&c=20201002) is (refs)
is (refs)![\partial_{t}\mathscr{P} [\psi(T),t]=-\partial_{\psi} V[\psi(t)]+\frac{1}{2}V[\psi(t)] \partial_{\psi} V[\psi(t)]]\mathscr{P}[\psi(t),t]+\frac{1}{2}\partial_{\psi}\partial_{\psi}[V[\psi(t)]^{2} \mathscr{P}[\psi(t),t]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cpartial_%7Bt%7D%5Cmathscr%7BP%7D+%5B%5Cpsi%28T%29%2Ct%5D%3D-%5Cpartial_%7B%5Cpsi%7D+V%5B%5Cpsi%28t%29%5D%2B%5Cfrac%7B1%7D%7B2%7DV%5B%5Cpsi%28t%29%5D+%5Cpartial_%7B%5Cpsi%7D+V%5B%5Cpsi%28t%29%5D%5D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%5D%2B%5Cfrac%7B1%7D%7B2%7D%5Cpartial_%7B%5Cpsi%7D%5Cpartial_%7B%5Cpsi%7D%5BV%5B%5Cpsi%28t%29%5D%5E%7B2%7D+%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%5D+%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
![\widehat{\psi}(t+\delta t)-\widehat{\psi}(T)=U[\psi(t)]\delta t +V[\psi(t)]{\displaystyle \int_{t}^{t+\delta t}}d\mathcal{B}(t')](https://s0.wp.com/latex.php?latex=%C2%A0%5Cwidehat%7B%5Cpsi%7D%28t%2B%5Cdelta+t%29-%5Cwidehat%7B%5Cpsi%7D%28T%29%3DU%5B%5Cpsi%28t%29%5D%5Cdelta+t+%2BV%5B%5Cpsi%28t%29%5D%7B%5Cdisplaystyle+%5Cint_%7Bt%7D%5E%7Bt%2B%5Cdelta+t%7D%7Dd%5Cmathcal%7BB%7D%28t%27%29+&bg=ffffff&fg=545454&s=0&c=20201002)
![\partial_{t}\mathscr{P}[\psi(t),t]=\partial_{\psi}U[\psi(t),t]\mathscr{P}[\psi(t),t]+\frac{1}{2}\partial_{\psi}\partial_{\psi}[V[\psi(t)]^{2}\mathscr{P}[\psi(t),t]](https://s0.wp.com/latex.php?latex=%5Cpartial_%7Bt%7D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%5D%3D%5Cpartial_%7B%5Cpsi%7DU%5B%5Cpsi%28t%29%2Ct%5D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%5D%2B%5Cfrac%7B1%7D%7B2%7D%5Cpartial_%7B%5Cpsi%7D%5Cpartial_%7B%5Cpsi%7D%5BV%5B%5Cpsi%28t%29%5D%5E%7B2%7D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%5D%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
 then this is a nonlinear diffusion equation for
then this is a nonlinear diffusion equation for ![\mathscr{P}[\psi(t),t]](https://s0.wp.com/latex.php?latex=%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%5D&bg=ffffff&fg=545454&s=0&c=20201002)
![\partial_{t}\mathscr{P}[\psi(t),t]=+\frac{1}{2} \partial_{\psi}\partial_{\psi}[V[\psi(t)]^{2}\mathscr{P}[\psi(t),t]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cpartial_%7Bt%7D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%5D%3D%2B%5Cfrac%7B1%7D%7B2%7D+%5Cpartial_%7B%5Cpsi%7D%5Cpartial_%7B%5Cpsi%7D%5BV%5B%5Cpsi%28t%29%5D%5E%7B2%7D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%5D%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
![\partial_{t}\mathscr{P}[\psi(t),t]=0](https://s0.wp.com/latex.php?latex=%C2%A0%5Cpartial_%7Bt%7D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%5D%3D0&bg=ffffff&fg=545454&s=0&c=20201002) so that
so that![G\mathscr{P}[\psi(t)]=\partial_{\psi} V[\psi(t),t]\mathscr{P}[\psi(t]+\frac{1}{2} \partial_{\psi}\partial_{\psi}[V[\psi(t)]^{-2}\mathscr{P}[D(t]=](https://s0.wp.com/latex.php?latex=%C2%A0G%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%5D%3D%5Cpartial_%7B%5Cpsi%7D+V%5B%5Cpsi%28t%29%2Ct%5D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%5D%2B%5Cfrac%7B1%7D%7B2%7D+%5Cpartial_%7B%5Cpsi%7D%5Cpartial_%7B%5Cpsi%7D%5BV%5B%5Cpsi%28t%29%5D%5E%7B-2%7D%5Cmathscr%7BP%7D%5BD%28t%5D%3D%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
 for the probability density is
for the probability density is![\mathscr{P}[\psi(t),t=\infty]= \bigg|\frac{C}{(V[\psi(t)]^{2}}\bigg| exp\bigg(2{\displaystyle \int_{\psi_{0}}}^{\psi(t)}\frac{U[\bar{\psi}(t)]}{(\Psi[\bar{\psi}(t)])^{2}}d\bar{\psi}(t)\bigg)](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%3D%5Cinfty%5D%3D+%5Cbigg%7C%5Cfrac%7BC%7D%7B%28V%5B%5Cpsi%28t%29%5D%5E%7B2%7D%7D%5Cbigg%7C+exp%5Cbigg%282%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B0%7D%7D%7D%5E%7B%5Cpsi%28t%29%7D%5Cfrac%7BU%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%7D%7B%28%5CPsi%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%29%5E%7B2%7D%7Dd%5Cbar%7B%5Cpsi%7D%28t%29%5Cbigg%29+%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
![{\displaystyle \int_{\psi(0)}^{\infty}}\mathscr{P}[\psi(t)]d\psi(t)={\displaystyle \int_{\psi_{0}}^{\infty}} \bigg|\frac{C}{(V[\psi(t)]^{2}}\bigg| exp\bigg(2{\displaystyle \int_{\psi_{0}}^{\psi(t)}}\frac{U[\bar{\psi}(t)]}{(V[\bar{\psi}(t)])^{2}}d\bar{\psi}(t)\bigg)=1](https://s0.wp.com/latex.php?latex=%C2%A0%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi%280%29%7D%5E%7B%5Cinfty%7D%7D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%5Dd%5Cpsi%28t%29%3D%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B0%7D%7D%5E%7B%5Cinfty%7D%7D+%5Cbigg%7C%5Cfrac%7BC%7D%7B%28V%5B%5Cpsi%28t%29%5D%5E%7B2%7D%7D%5Cbigg%7C%C2%A0exp%5Cbigg%282%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B0%7D%7D%5E%7B%5Cpsi%28t%29%7D%7D%5Cfrac%7BU%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%7D%7B%28V%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%29%5E%7B2%7D%7Dd%5Cbar%7B%5Cpsi%7D%28t%29%5Cbigg%29%3D1+&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathscr{P}[\psi(t),t=\infty]=](https://s0.wp.com/latex.php?latex=%C2%A0+%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%3D%5Cinfty%5D%3D+&bg=ffffff&fg=545454&s=0&c=20201002)
![\frac{\bigg|\frac{1}{(V[\psi(t),t=\infty]^{2}}\bigg| exp\bigg(2{\displaystyle \int_{\psi_{0}}^{\psi(t)}}\frac{iU[\bar{\psi}(t)]} {(V[\bar{\psi}(t)])^{2}}d \bar{\psi}(t)\bigg)}{{\displaystyle \int_{\psi_{0}}^{\infty}} \bigg|\frac{1}{(V[\psi(t)]^{2}} exp\bigg(2{\displaystyle \int_{\psi_{0}}^{\psi(t)}}\frac{U[\bar{\psi}(t)]}{(V[\bar{\psi}(t)])^{2}} d \bar{\psi}(t)\bigg)}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cbigg%7C%5Cfrac%7B1%7D%7B%28V%5B%5Cpsi%28t%29%2Ct%3D%5Cinfty%5D%5E%7B2%7D%7D%5Cbigg%7C%C2%A0exp%5Cbigg%282%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B0%7D%7D%5E%7B%5Cpsi%28t%29%7D%7D%5Cfrac%7BiU%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%7D+%7B%28V%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%29%5E%7B2%7D%7Dd+%5Cbar%7B%5Cpsi%7D%28t%29%5Cbigg%29%7D%7B%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B0%7D%7D%5E%7B%5Cinfty%7D%7D+%5Cbigg%7C%5Cfrac%7B1%7D%7B%28V%5B%5Cpsi%28t%29%5D%5E%7B2%7D%7D+exp%5Cbigg%282%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B0%7D%7D%5E%7B%5Cpsi%28t%29%7D%7D%5Cfrac%7BU%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%7D%7B%28V%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%29%5E%7B2%7D%7D+d+%5Cbar%7B%5Cpsi%7D%28t%29%5Cbigg%29%7D+%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{P}[\widehat{\psi}(t),t=\infty]={\displaystyle \int_{\psi(0)}^{\psi(t)}}\mathscr{P}[\psi(t),t=\infty]dD(t)=](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BP%7D%5B%5Cwidehat%7B%5Cpsi%7D%28t%29%2Ct%3D%5Cinfty%5D%3D%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi%280%29%7D%5E%7B%5Cpsi%28t%29%7D%7D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%3D%5Cinfty%5DdD%28t%29%3D&bg=ffffff&fg=545454&s=0&c=20201002)
![{\displaystyle \int_{\psi(0)}^{\psi(t)}}\frac{\bigg|\frac{1}{(V[\psi(t)]^{2}}\bigg| exp\bigg(2{\displaystyle \int_{\psi_{0}}^{\psi(t)}}\frac{U[\bar{\psi}(t)]} {(V[\bar{\psi}(t)])^{2}}d\bar{\psi}(t)\bigg)}{{\displaystyle \int_{\psi_{0}}^{\infty}} \bigg|\frac{1}{(V[\psi(t)]^{2}}\bigg| exp\bigg(2{\displaystyle \int_{\psi_{0}}^{\psi(t)}}\frac{U[\bar{\psi}(t)]}{(V[\bar{\psi}(t)])^{2}} d\bar{\psi}(t)\bigg)} d\psi(t)](https://s0.wp.com/latex.php?latex=%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi%280%29%7D%5E%7B%5Cpsi%28t%29%7D%7D%5Cfrac%7B%5Cbigg%7C%5Cfrac%7B1%7D%7B%28V%5B%5Cpsi%28t%29%5D%5E%7B2%7D%7D%5Cbigg%7C+exp%5Cbigg%282%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B0%7D%7D%5E%7B%5Cpsi%28t%29%7D%7D%5Cfrac%7BU%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%7D+%7B%28V%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%29%5E%7B2%7D%7Dd%5Cbar%7B%5Cpsi%7D%28t%29%5Cbigg%29%7D%7B%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B0%7D%7D%5E%7B%5Cinfty%7D%7D+%5Cbigg%7C%5Cfrac%7B1%7D%7B%28V%5B%5Cpsi%28t%29%5D%5E%7B2%7D%7D%5Cbigg%7C+exp%5Cbigg%282%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B0%7D%7D%5E%7B%5Cpsi%28t%29%7D%7D%5Cfrac%7BU%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%7D%7B%28V%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%29%5E%7B2%7D%7D%C2%A0d%5Cbar%7B%5Cpsi%7D%28t%29%5Cbigg%29%7D+d%5Cpsi%28t%29+&bg=ffffff&fg=545454&s=0&c=20201002)
 at
at ![\mathbf{P}[\widehat{\psi}(t)<\infty,t=\infty]={\displaystyle \int_{\psi(0)}^{\infty}}\mathscr{P}[\psi(t),t=\infty]d\psi(t)=](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BP%7D%5B%5Cwidehat%7B%5Cpsi%7D%28t%29%3C%5Cinfty%2Ct%3D%5Cinfty%5D%3D%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi%280%29%7D%5E%7B%5Cinfty%7D%7D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%3D%5Cinfty%5Dd%5Cpsi%28t%29%3D&bg=ffffff&fg=545454&s=0&c=20201002)
![{\displaystyle \int_{\psi(0)}^{\infty}}\frac{\bigg|\frac{1}{(V[\psi(t)]^{2}}\bigg| exp\bigg(2{\displaystyle \int_{\psi_{0}}^{\psi(t)}}\frac{U[\bar{\psi}(t)]} {(V[\bar{\psi}(t)])^{2}}d\bar{\psi}(t)\bigg)}{{\displaystyle \int_{\psi_{0}}^{\infty}} \bigg|\frac{1}{(V[\psi(t)]^{2}}\bigg| exp\bigg(2{\displaystyle \int_{\psi_{0}}^{\psi(t)}}\frac{U[\bar{\psi}(t)]}{(V[\bar{\psi}(t)])^{2}} d\bar{\psi}(t)\bigg)} d\psi(t)=1](https://s0.wp.com/latex.php?latex=%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi%280%29%7D%5E%7B%5Cinfty%7D%7D%5Cfrac%7B%5Cbigg%7C%5Cfrac%7B1%7D%7B%28V%5B%5Cpsi%28t%29%5D%5E%7B2%7D%7D%5Cbigg%7C%C2%A0exp%5Cbigg%282%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B0%7D%7D%5E%7B%5Cpsi%28t%29%7D%7D%5Cfrac%7BU%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%7D+%7B%28V%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%29%5E%7B2%7D%7Dd%5Cbar%7B%5Cpsi%7D%28t%29%5Cbigg%29%7D%7B%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B0%7D%7D%5E%7B%5Cinfty%7D%7D+%5Cbigg%7C%5Cfrac%7B1%7D%7B%28V%5B%5Cpsi%28t%29%5D%5E%7B2%7D%7D%5Cbigg%7C+exp%5Cbigg%282%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B0%7D%7D%5E%7B%5Cpsi%28t%29%7D%7D%5Cfrac%7BU%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%7D%7B%28V%5B%5Cbar%7B%5Cpsi%7D%28t%29%5D%29%5E%7B2%7D%7D%C2%A0d%5Cbar%7B%5Cpsi%7D%28t%29%5Cbigg%29%7D+d%5Cpsi%28t%29%3D1+&bg=ffffff&fg=545454&s=0&c=20201002)
![V[\psi(t)]=0](https://s0.wp.com/latex.php?latex=V%5B%5Cpsi%28t%29%5D%3D0&bg=ffffff&fg=545454&s=0&c=20201002) the solution reduces to
the solution reduces to![\mathbf{P}[\widehat{\psi}(t)<\infty]=\lim_{\psi(t)\rightarrow\infty}{\displaystyle \int_{\psi(0)}^{\psi(t)}}\mathscr{P}[\psi(t),t=\infty]=](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BP%7D%5B%5Cwidehat%7B%5Cpsi%7D%28t%29%3C%5Cinfty%5D%3D%5Clim_%7B%5Cpsi%28t%29%5Crightarrow%5Cinfty%7D%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi%280%29%7D%5E%7B%5Cpsi%28t%29%7D%7D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%3D%5Cinfty%5D%3D&bg=ffffff&fg=545454&s=0&c=20201002)
![\lim_{\psi(t)\rightarrow\infty}\frac{\displaystyle{\int_{\psi(0)}^{\psi(t)}}\bigg|\frac{1}{(V[\psi(t)]^{2}}\bigg|}{{\displaystyle \int_{\psi_{0}}^{\infty}} \bigg|\frac{1}{(V[\psi(t)]^{2}}\bigg|}=1](https://s0.wp.com/latex.php?latex=%C2%A0%5Clim_%7B%5Cpsi%28t%29%5Crightarrow%5Cinfty%7D%5Cfrac%7B%5Cdisplaystyle%7B%5Cint_%7B%5Cpsi%280%29%7D%5E%7B%5Cpsi%28t%29%7D%7D%5Cbigg%7C%5Cfrac%7B1%7D%7B%28V%5B%5Cpsi%28t%29%5D%5E%7B2%7D%7D%5Cbigg%7C%7D%7B%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B0%7D%7D%5E%7B%5Cinfty%7D%7D+%5Cbigg%7C%5Cfrac%7B1%7D%7B%28V%5B%5Cpsi%28t%29%5D%5E%7B2%7D%7D%5Cbigg%7C%7D%3D1%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002) T
T![d\widehat{\psi}(t)=V[\psi(t)]\otimes d\widehat{\mathcal{B}}(t)](https://s0.wp.com/latex.php?latex=d%5Cwidehat%7B%5Cpsi%7D%28t%29%3DV%5B%5Cpsi%28t%29%5D%5Cotimes+d%5Cwidehat%7B%5Cmathcal%7BB%7D%7D%28t%29&bg=ffffff&fg=545454&s=0&c=20201002) defined for all
defined for all  with initial matter density
with initial matter density  the Fokker-Planck diffusion equation now becomes (ref)
the Fokker-Planck diffusion equation now becomes (ref)![\partial_{t}\mathscr{P}[\psi(t),t]=+\frac{1}{2} \partial_{\partial}\partial_{\psi}((\psi(t))^{4}(\psi(t)-1))\mathscr{P}[\psi(t),t]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cpartial_%7Bt%7D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%5D%3D%2B%5Cfrac%7B1%7D%7B2%7D+%5Cpartial_%7B%5Cpartial%7D%5Cpartial_%7B%5Cpsi%7D%28%28%5Cpsi%28t%29%29%5E%7B4%7D%28%5Cpsi%28t%29-1%29%29%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%5D%C2%A0&bg=ffffff&fg=545454&s=0&c=20201002)

![G\mathbf{\mathscr{P}}[\psi(t),t=\infty]](https://s0.wp.com/latex.php?latex=%C2%A0G%5Cmathbf%7B%5Cmathscr%7BP%7D%7D%5B%5Cpsi%28t%29%2Ct%3D%5Cinfty%5D&bg=ffffff&fg=545454&s=0&c=20201002) =
= ![\frac{1}{2}\partial_{\psi}\partial_{\psi}((\psi(t))^{4}(\psi(t)-1))\mathbf{\mathscr{P}}[\psi(t),t=\infty]=0](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D%5Cpartial_%7B%5Cpsi%7D%5Cpartial_%7B%5Cpsi%7D%28%28%5Cpsi%28t%29%29%5E%7B4%7D%28%5Cpsi%28t%29-1%29%29%5Cmathbf%7B%5Cmathscr%7BP%7D%7D%5B%5Cpsi%28t%29%2Ct%3D%5Cinfty%5D%3D0+&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathbf{P}[\psi(T)<\infty,t=\infty]=\lim_{\psi(t)\rightarrow\infty} {\displaystyle \int_{\psi_{\epsilon}}^{\psi(t)}}\mathscr{P}[\psi(t),t=\infty]d\psi(t)](https://s0.wp.com/latex.php?latex=%C2%A0+%5Cmathbf%7BP%7D%5B%5Cpsi%28T%29%3C%5Cinfty%2Ct%3D%5Cinfty%5D%3D%5Clim_%7B%5Cpsi%28t%29%5Crightarrow%5Cinfty%7D+%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B%5Cepsilon%7D%7D%5E%7B%5Cpsi%28t%29%7D%7D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%3D%5Cinfty%5Dd%5Cpsi%28t%29&bg=ffffff&fg=545454&s=0&c=20201002)
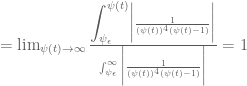
![d\widehat{\psi}(t)=V[\psi(t)]\circ d\widehat{\mathcal{B}}(t)](https://s0.wp.com/latex.php?latex=d%5Cwidehat%7B%5Cpsi%7D%28t%29%3DV%5B%5Cpsi%28t%29%5D%5Ccirc+d%5Cwidehat%7B%5Cmathcal%7BB%7D%7D%28t%29&bg=ffffff&fg=545454&s=0&c=20201002) defined for all
defined for all the Fokker-Planck diffusion equation is as before(ref)
the Fokker-Planck diffusion equation is as before(ref)![\partial_{t}\mathscr{P}[[\psi(t),t]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cpartial_%7Bt%7D%5Cmathscr%7BP%7D%5B%5B%5Cpsi%28t%29%2Ct%5D&bg=ffffff&fg=545454&s=0&c=20201002)
![=+\frac{1}{2} \partial_{\psi}\partial_{\psi}\psi^{4}(t)(\psi(t)-1))\mathbf{\mathscr{P}}[\psi(t),t]](https://s0.wp.com/latex.php?latex=%3D%2B%5Cfrac%7B1%7D%7B2%7D+%5Cpartial_%7B%5Cpsi%7D%5Cpartial_%7B%5Cpsi%7D%5Cpsi%5E%7B4%7D%28t%29%28%5Cpsi%28t%29-1%29%29%5Cmathbf%7B%5Cmathscr%7BP%7D%7D%5B%5Cpsi%28t%29%2Ct%5D+&bg=ffffff&fg=545454&s=0&c=20201002)
![G\mathscr{P}[\psi(t),t=\infty]=\frac{1}{2}\partial_{\psi}\partial_{\psi}\psi^{4}(t))(\psi(t)-1))\mathscr{P}[\psi(t),t=\infty]=0](https://s0.wp.com/latex.php?latex=%C2%A0G%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%3D%5Cinfty%5D%3D%5Cfrac%7B1%7D%7B2%7D%5Cpartial_%7B%5Cpsi%7D%5Cpartial_%7B%5Cpsi%7D%5Cpsi%5E%7B4%7D%28t%29%29%28%5Cpsi%28t%29-1%29%29%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%3D%5Cinfty%5D%3D0+&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathscr{P}[\psi(t),t=\infty]=](https://s0.wp.com/latex.php?latex=%C2%A0%C2%A0%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%3D%5Cinfty%5D%3D&bg=ffffff&fg=545454&s=0&c=20201002)
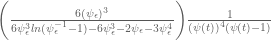
 is finite at
is finite at  is now given by (-) as
is now given by (-) as![\mathbf{P}[\psi(t)<\infty,t=\infty]={\displaystyle\int_{\psi_{\epsilon}}^{\infty}}\mathscr{P}[\psi(t),t=\infty]](https://s0.wp.com/latex.php?latex=%C2%A0%5Cmathbf%7BP%7D%5B%5Cpsi%28t%29%3C%5Cinfty%2Ct%3D%5Cinfty%5D%3D%7B%5Cdisplaystyle%5Cint_%7B%5Cpsi_%7B%5Cepsilon%7D%7D%5E%7B%5Cinfty%7D%7D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%3D%5Cinfty%5D&bg=ffffff&fg=545454&s=0&c=20201002)

![\mathbf{P}[\psi(t)<\infty,t=\infty]={\displaystyle \int_{\psi_{\epsilon}}^{\infty}}\mathscr{P}[\psi(t),t=\infty]](https://s0.wp.com/latex.php?latex=%C2%A0+%5Cmathbf%7BP%7D%5B%5Cpsi%28t%29%3C%5Cinfty%2Ct%3D%5Cinfty%5D%3D%7B%5Cdisplaystyle+%5Cint_%7B%5Cpsi_%7B%5Cepsilon%7D%7D%5E%7B%5Cinfty%7D%7D%5Cmathscr%7BP%7D%5B%5Cpsi%28t%29%2Ct%3D%5Cinfty%5D+&bg=ffffff&fg=545454&s=0&c=20201002) =
= 
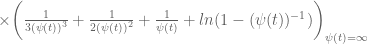

 since
since 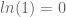 so that (-) reduces to
so that (-) reduces to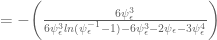


 or
or  and
and  , for density and pressures, and that the space-time manifold
, for density and pressures, and that the space-time manifold  must satisfy appropriate casuality conditions such as global hyperbolicity.
must satisfy appropriate casuality conditions such as global hyperbolicity. is formed around a sufficiently heavy collapsing star which is well above the Oppenheimer-Volkoff limit, and which has exhausted its fuel. The star can then no longer provide the thermal and radiative transport/pressure required to maintain the equilibrium condition required by the Tolman-Oppenheimer-Volkoff equation –or its Newtonian limit–and which kept it stable for billions of years. Most of the stars in the night sky are within the Oppenheimer-Volkoff limit and will ultimately collapse to super-dense white dwarfs or neutron stars following a red giant phase of nuclear helium burning. Since the (thermo) nuclear reaction rates
is formed around a sufficiently heavy collapsing star which is well above the Oppenheimer-Volkoff limit, and which has exhausted its fuel. The star can then no longer provide the thermal and radiative transport/pressure required to maintain the equilibrium condition required by the Tolman-Oppenheimer-Volkoff equation –or its Newtonian limit–and which kept it stable for billions of years. Most of the stars in the night sky are within the Oppenheimer-Volkoff limit and will ultimately collapse to super-dense white dwarfs or neutron stars following a red giant phase of nuclear helium burning. Since the (thermo) nuclear reaction rates  for fusion of hydrogen (and heavier elements) in its core varies as
for fusion of hydrogen (and heavier elements) in its core varies as 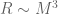 , heavier stars burn through their fuel much more rapidly–a star 10 time heavier than the sun will burn through its fuel about a 1000 times faster. In reality, the heaviest stars will supernova but a superheavy central core can still completely collapse to a point.
, heavier stars burn through their fuel much more rapidly–a star 10 time heavier than the sun will burn through its fuel about a 1000 times faster. In reality, the heaviest stars will supernova but a superheavy central core can still completely collapse to a point.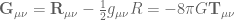

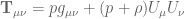 and
and 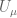 is the velocity 4-vector defined so that
is the velocity 4-vector defined so that  . Since the fluid is at rest
. Since the fluid is at rest  and
and 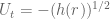 . It is a standard (albeit tedious) calculation to derive the Riemann tensor components and Einstein field equations for a spherical perfect-fluid star (refs) with an exterior metric
. It is a standard (albeit tedious) calculation to derive the Riemann tensor components and Einstein field equations for a spherical perfect-fluid star (refs) with an exterior metric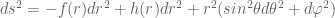




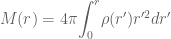 .
. for a star of radius
for a star of radius  so the metric (-) smoothly joins into the vacuum Schwarzchild metric with total mass
so the metric (-) smoothly joins into the vacuum Schwarzchild metric with total mass  . Computing the total mass M of the star of radius R by integrating the density over its volume gives
. Computing the total mass M of the star of radius R by integrating the density over its volume gives

 , giving the mass up to given radius within the star, now “runs” within the interior region
, giving the mass up to given radius within the star, now “runs” within the interior region  then
then 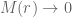 fast enough to remove the central singularity as
fast enough to remove the central singularity as  and
and  remains finite as
remains finite as 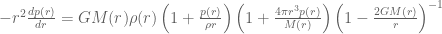

 . The relativistic factors in the Tolman-Oppenheimer-Volkoff equations are all positive definite so that for any value of r, Newtonian gravity seems to become amplified–relativistic corrections essentially strengthen the pull of gravitation.
. The relativistic factors in the Tolman-Oppenheimer-Volkoff equations are all positive definite so that for any value of r, Newtonian gravity seems to become amplified–relativistic corrections essentially strengthen the pull of gravitation. . When its fuel is exhausted, the star can longer provide the pressure gradient required in the TOV equation so that
. When its fuel is exhausted, the star can longer provide the pressure gradient required in the TOV equation so that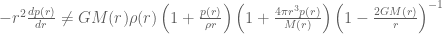
 on spacetimes where the Einstein equations hold along with the strong or weak energy conditions for matter. The accepted standard definition of a singularity free spaceime is as follows:
on spacetimes where the Einstein equations hold along with the strong or weak energy conditions for matter. The accepted standard definition of a singularity free spaceime is as follows: is singularity free if it is geodesically complete. A trapped surface
is singularity free if it is geodesically complete. A trapped surface  is defined as follows: Let
is defined as follows: Let  be a globally hyperbolic spacetime with Cauchy foliation
be a globally hyperbolic spacetime with Cauchy foliation  . A compact 2-dimensional smooth space-like submanifold
. A compact 2-dimensional smooth space-like submanifold  , bounding a compact domain
, bounding a compact domain 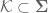 is a trapped surface if
is a trapped surface if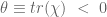 on
on 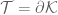 with expansion
with expansion 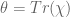 and
and  for tangent vectors
for tangent vectors 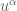
 , where the black-hole region
, where the black-hole region 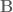 is the boundary of the casual past of future-null infinity; that is
is the boundary of the casual past of future-null infinity; that is  . The first singularity theorem was given by Penrose in 1965 in relation to trapped surfaces and future-directed null geodesics from the surface
. The first singularity theorem was given by Penrose in 1965 in relation to trapped surfaces and future-directed null geodesics from the surface
 be a connected globally hyperbolic spacetime with Cauchy hypersurfaces
be a connected globally hyperbolic spacetime with Cauchy hypersurfaces 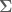 and
and 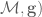 is a development of initial Cauchy data. let
is a development of initial Cauchy data. let  . For all null vectors
. For all null vectors  , the strong energy condition (SEC)
, the strong energy condition (SEC)  implies
implies  . Let
. Let 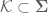 with
with  . Then at least one inextendible future-directed orthogonal geodesic from
. Then at least one inextendible future-directed orthogonal geodesic from  has affine length no greater than
has affine length no greater than  where
where  .
.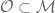 be an open subset of
be an open subset of 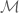 . A congruence
. A congruence  in
in  is a set of curves or geodesics
is a set of curves or geodesics  such that for each
such that for each  , one and only one geodesic
, one and only one geodesic  passes through
passes through  . The associated tangent vectors for the congruence are
. The associated tangent vectors for the congruence are  so that
so that  for timelike geodesics and
for timelike geodesics and 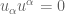 for null geodesics. Defining
for null geodesics. Defining 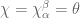 .
. and has 4-velocity
and has 4-velocity 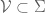 be volume elements on spacelike Cauchy surfaces/slices
be volume elements on spacelike Cauchy surfaces/slices  be area elements on null slices transverse to a null geodesic congruence. (Latin indices can be on these hypersurfaces):
be area elements on null slices transverse to a null geodesic congruence. (Latin indices can be on these hypersurfaces):





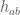 is the spacelike positive-definite3-metric or 2-metric on $\latex \Sigma$ or
is the spacelike positive-definite3-metric or 2-metric on $\latex \Sigma$ or 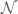 . The trace of the extrinsic curvature of
. The trace of the extrinsic curvature of  . The geodesic deviation equation or Jacobi equation gives the Raychaudhuri equation so that in terms of
. The geodesic deviation equation or Jacobi equation gives the Raychaudhuri equation so that in terms of 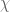
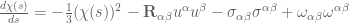
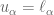 , the Raychauhuri equation essentially describes geometric optics in curved space and has a similar form so that
, the Raychauhuri equation essentially describes geometric optics in curved space and has a similar form so that
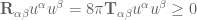
![\frac{d\chi(s)}{ds}=-\alpha(\chi(s))^{2}=q\equiv \alpha[(\chi(s))^{2}+q/\alpha]\equiv H(\chi(s))](https://s0.wp.com/latex.php?latex=%C2%A0%5Cfrac%7Bd%5Cchi%28s%29%7D%7Bds%7D%3D-%5Calpha%28%5Cchi%28s%29%29%5E%7B2%7D%3Dq%5Cequiv+%5Calpha%5B%28%5Cchi%28s%29%29%5E%7B2%7D%2Bq%2F%5Calpha%5D%5Cequiv+H%28%5Cchi%28s%29%29+&bg=ffffff&fg=545454&s=0&c=20201002)
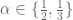 . Since
. Since 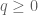 then
then
 , for the trace
, for the trace  of the extrinsic curvature of a trapped surface
of the extrinsic curvature of a trapped surface 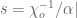 or
or  . It can be proved that this is more than a blowup in the caustic but that the spacetime is itself geodesically incomplete (refs.). For any points
. It can be proved that this is more than a blowup in the caustic but that the spacetime is itself geodesically incomplete (refs.). For any points  a conjugate point is inflicted at q relative to p if
a conjugate point is inflicted at q relative to p if  .
.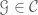 be a geodesic of the congruence
be a geodesic of the congruence  with
with 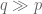 then q is a conjugate point relative to p if
then q is a conjugate point relative to p if 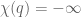

Recent Comments